在软件基础设施领域,人们开始越来越重视代码的性能优化,在满足其可实现功能完整的同时,若可逐步去优化代码,则能在相同硬件条件下达到更好的工作效率,进一步提高业务生产效率。尤其是大数据领域,比如 OLAP 数据库通常服务于海量数据即席查询分析的场景,一些看似不起眼的底层调优却能在数据量级上进行优化叠加,从而达到优化系统整体分析查询的性能目的,可谓星星之火可以燎原。
在这里主要向大家做一个 Databend 性能调优相关的分享,共会分为三次向大家介绍,如下所示:
1、基础篇:代码调优的前置知识 2、实践篇1:Databend 源码性能调优实践 3、实践篇2:Databend 的 Group By 聚合查询为什么跑的这么快?
在后续 Databend 打磨的过程中,我们也将介绍更多关于性能优化相关的设计,比如Databend 新的 pipeline workflow 模型设计,Databend 如何将向量化和编译执行结合等。
1、存储器层次结构
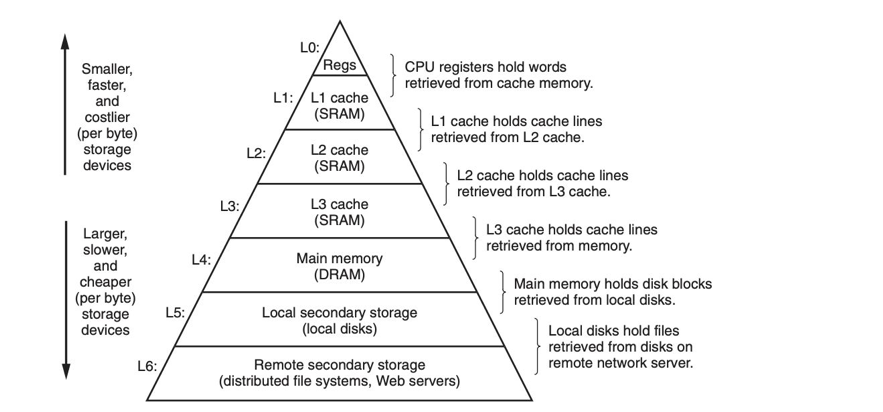
随着科技的不断发展,大家一定对存储器越来越不陌生了,下图中所呈现的内容为存储器的金字塔模型。
图中存储器层次结构从上往下为:寄存器、L1 Cache、L2 Cache、L3 Cache、内存、SSD/HDD 硬盘。每个层次结构都有着不同的容量、缓存时间。从上往下来看,存储容量越大,但速度越慢,成本越低,往上来看则相反。通常编写高性能代码的原则在于将数据访问靠近上层,让数据离 CPU 靠近,减少数据访问的开销。
2、延迟
上图了解了通用的存储器,我们再来介绍下存储器大概的访问延迟。延迟也表示为完成计算或者 I/O 请求所需的时间,为了量化这个指标,也会通过各种计算来衡量这个性能,例如 IOPS、吞吐量等等。
下图[1]为大家列出几个每个程序员都应该了解的延迟数字,这些数字代表了计算机各类操作的一个大概耗时:

Jeff dean 曾要求这些延迟所有程序员都应该熟记于心, 它让我们在代码调优的时候能有一个客观的度量值。
3、局部性原理
基于现代计算机存储器的设计,程序在执行的过程中存在着很强的局部性,局部性又分为了「时间局部性」和「空间局部性」。
时间局部性: 时间局部性是指当一个数据在某一时间被访问后,则有可能在不久后被再次访问,所以我们看到很多程序会利用缓存来加速数据访问。
空间局部性: 也称数据局部性,得益于存储器缓存的设计,它是指当一个数据在某一地址被访问了之后,则访问它相邻位置的数据也会更加高效,常见于循环访问数组数据中。
所以当我们利用好这些局部性原理,可以编写更加“局部性”的代码来提升 CPU 的性能和利用率。下图中展示为英特尔公司的 Core i7 Haswell 处理器的存储器山模型,x轴表示存储器的容量大小,y 轴表示程序访问的步长,z 轴表示存储器访问吞吐,其3D模型则为图中所示。
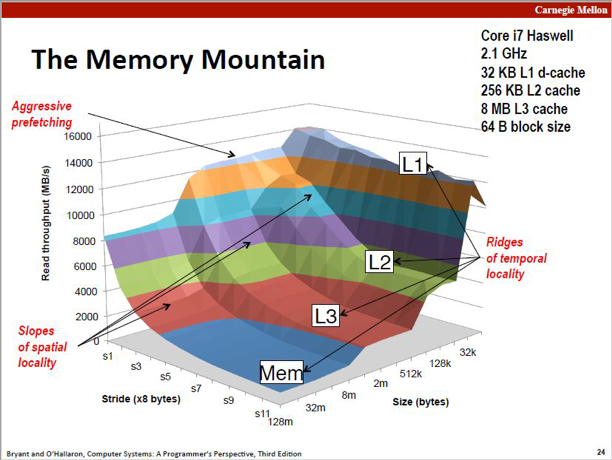
随着存储器的容量提升,性能基本呈倒退趋势,但如果步长可以在一定短的区间内,可以非常好利用数据局部性的优化,比如 CPU 的 prefetch,从而达到提升吞吐的作用。
4、数据局部性示例
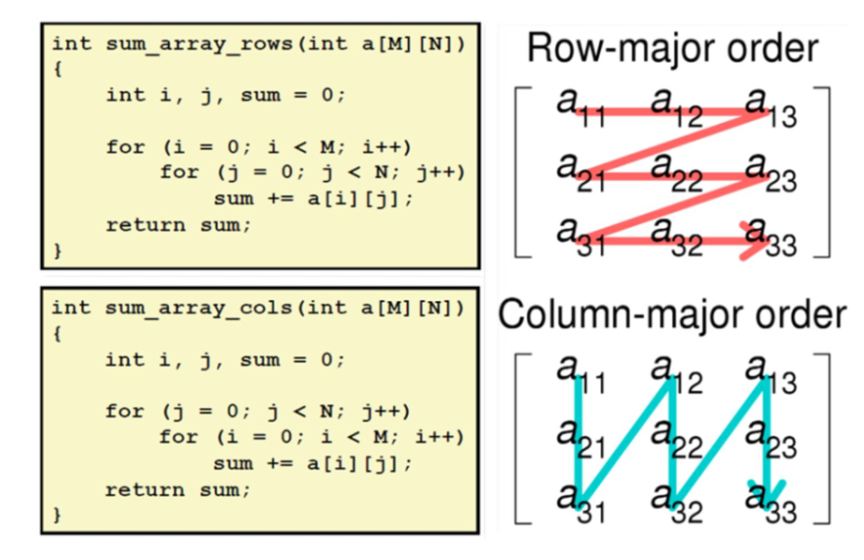
这里再介绍一个矩阵的行优先和列优先遍历访问的例子,我们遍历矩阵求和的方式是先循环行方式遍历还是先循环列方式进行遍历。如图所示,在 Row-major order 中,行遍历求和的性能远高于列遍历求和的性能,因为行遍历的方式数据能有更好的局部性,相邻的数据可以在 CPU cache 中,数据可以以非常高效的方式访问。同时,编译器也能对局部性强的数据访问进行优化,生成更加高性能的代码,比如自动向量化。
5、性能表达
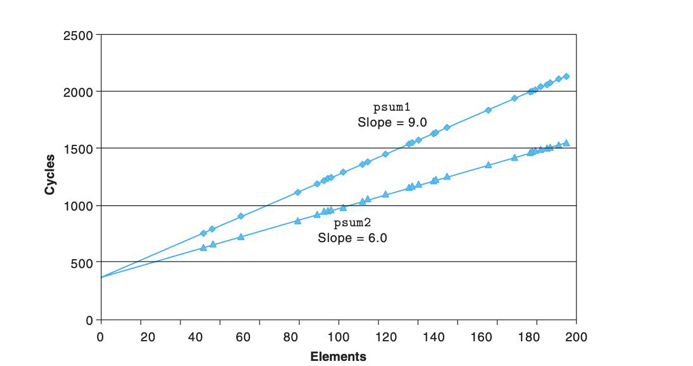
这里引用 CASAPP [2] 中 Prefix-sum functions 的例子,在 psum1 函数中做的是直接使用一个 for 循环做加总求和,在 psum2 中,对循环进行展开,步长为 2 进行遍历。我们对两个函数设置不同的循环次数,每次运行代码都能得到一个 CPU 时钟结果,将结果运用最小二乘法可以拟合成下面的两条直线,直线的效率对应的就是函数性能的开销。可以得出 psum2 的性能明显优于 psum1。

6、实用工具和脚本介绍
在基础篇的后面,介绍下 Databend 中常见的调优方式。
- Print & Log & Tracing metrics
(1) 最常见的还是通过日志打印耗时,或者将耗时输出到监控系统中
(2) prometheus, jaejer [3]
-
Perf is a good tool, pprof, flamegraph
(1) How to profile databend [4]
(2) Cargo flamegraph crate [5]
-
cargo bench & criterion [6]
-
databend-benchmark [7]
-
ignore function && progress [8]
7、文章相关引用
[1]https://colin-scott.github.io/personal_website/research/interactive_latency.html [2]CS:APP3e, Bryant and O'Hallaron (cmu.edu) [3]ISSUE-3627: adding distributed tracing instrumentation to query by dantengsky · Pull Request #3628 · datafuselabs/databend (github.com) [4]How to profile Databend | Databend [5]flamegraph-rs/flamegraph: Easy flamegraphs for Rust projects and everything else, without Perl or pipes <3 (github.com) [6]bheisler/criterion.rs: Statistics-driven benchmarking library for Rust (github.com) [7]databend/databend-benchmark.rs at main · datafuselabs/databend (github.com) [8]databend/perfs.yaml at 9393f5cf7da5827132acd479185878726caf58bf · datafuselabs/databend (github.com)
评论区
写评论还没有评论