如何在面试中确定 Rust 程序员水平?
对于这个问题,张汉东老师在 RustFriday 飞书群线上沙龙第十三期中进行了分享:
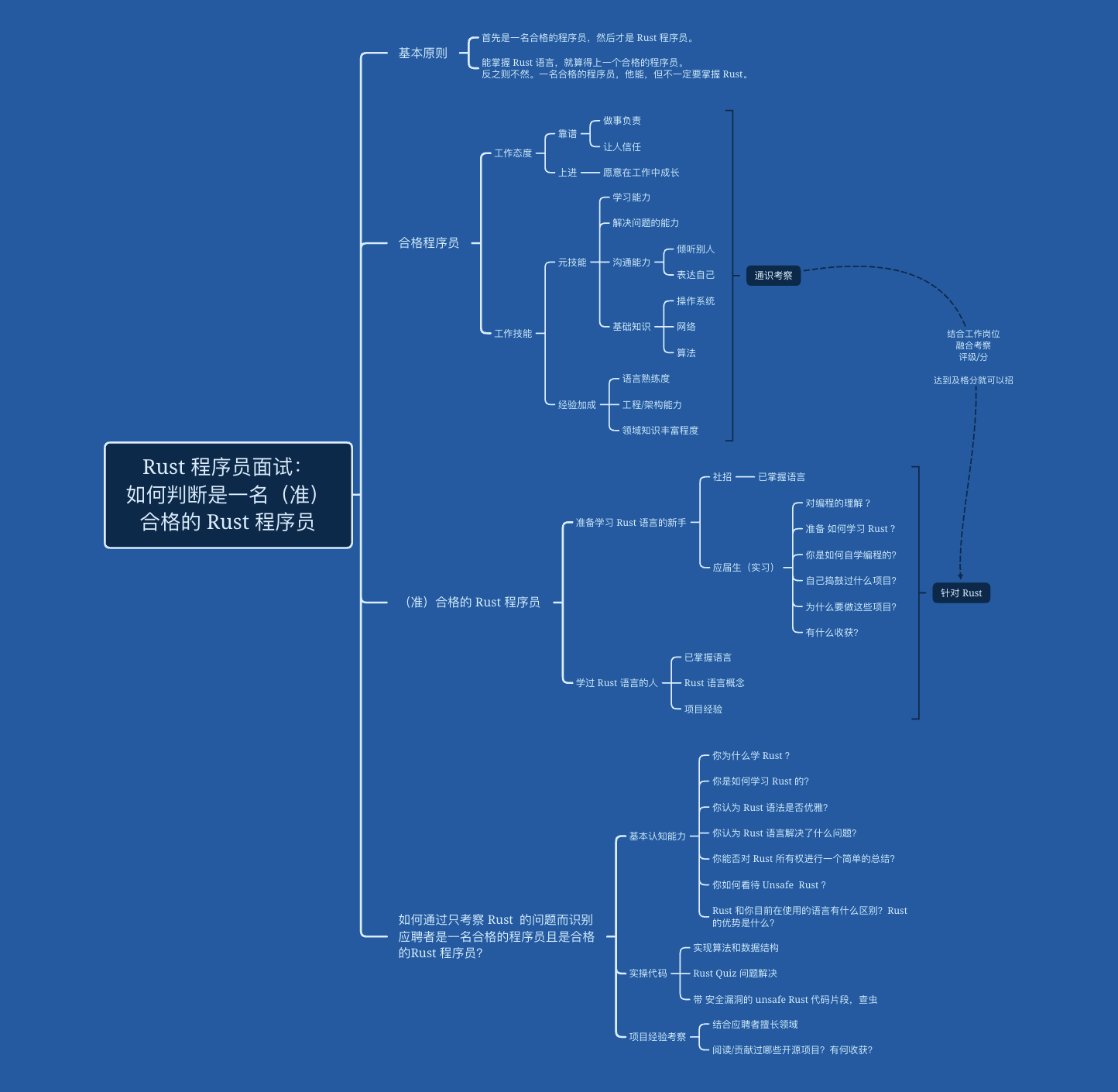
还有一张导图很好地提供了一个结构化的框架:
Pushgen: 用于处理范围和数据流的推式设计模式
这样使用:
# fn process(x: i32) {}
# let data = [1, 2, 3, 4, 5];
for item in data.iter().filter(|x| *x % 2 == 0).map(|x| x * 3) {
process(item);
}
// 可以写成
use pushgen::{SliceGenerator, GeneratorExt};
# fn process(_x: i32) {}
# let data = [1, 2, 3, 4, 5];
// Assume data is a slice
SliceGenerator::new(&data).filter(|x| *x % 2 == 0).map(|x| x * 3).for_each(process);
GitHub 地址:AndWass/pushgen
这里还有一个对比:transrangers/rust.md at master · joaquintides/transrangers
30 行的 TCP 代理
博客地址:zeke | tcp-proxy
GitHub 地址:ZekeMedley/tcp-proxy: Simple Rust TCP proxy using Tokio
核心代码:
async fn proxy(client: &str, server: &str) -> io::Result<()> {
let listener = TcpListener::bind(client).await?;
loop {
let (eyeball, _) = listener.accept().await?;
let origin = TcpStream::connect(server).await?;
// 将连接分为读写
let (mut eread, mut ewrite) = eyeball.into_split();
let (mut oread, mut owrite) = origin.into_split();
// 生成线程复制
let e2o = tokio::spawn(async move { io::copy(&mut eread, &mut owrite).await });
let o2e = tokio::spawn(async move { io::copy(&mut oread, &mut ewrite).await });
// 如果连接某一端关闭了,则关闭另一端
select! {
_ = e2o => println!("e2o done"),
_ = o2e => println!("o2e done"),
}
}
}
使用:
# 代理 1212 到 1313
$ cargo run -- -e 0.0.0.0:1212 -o 127.0.0.1:1313
# 监听 1313 上的 tcp 连接
$ nc -l 1313
# 建立到 1212 的连接,确认是否转发
$ echo hello | nc 127.0.0.1 1212
是的,又一个 Hands-on,For 2D Game
Ebook:Hands-on Rust: Effective Learning through 2D Game Development and Play by Herbert Wolverson
代码开源,书要钱:)
Yore:根据 OEM 代码页解码 / 编码字符集的 Rust 库
特点:
- 快
- 最小内存使用
- 支持多种代码页
- 支持重新定义 ascii (<0x80) 的代码页
来自维基百科的解释:
代码页:字符编码的别名,也称**内码表**,是特定语言的字符集的一张表。
字符编码(英语: Character encoding)、 字集码是把字符集中的字符编码为指定集合中某一对象(例如:比特模式、自然数序列、 8 位组或者电脉冲),以便文本在计算机中存储和通过通信网络的传递。常见的例子包括将拉丁字母表编码成摩斯电码和 ASCII。其中,ASCII 将字母、数字和其它符号 编号,并用 7 比特的二进制来表示这个整数。通常会额外使用一个扩充的比特,以便于以 1 个字节的方式存储。
在计算机科学及相关领域当中,内码指的是 “将信息编码后,透过某种方式存储在特定记忆设备时,设备内部的编码形式”。在不同的系统中,会有不同的内码。在以往的英文系统中,内码为 ASCII。 在繁体中文系统中,目前常用的内码为 大五码。在简体中文系统中,内码则为国标码。为了软件开发方便,如国际化与本地化,现在许多系统会使用 Unicode 做为内码,常见的操作系统 Windows、Mac OS X、Linux 皆如此。许多 编程语言也采用 Unicode 为内码,如 Java、Python 3。
简单使用:
use yore::code_pages::{CP857, CP850};
// Vec contains ascii "text"
let bytes = vec![116, 101, 120, 116];
// notice that decoding CP850 can't fail because it is completely defined
assert_eq!(CP850.decode(&bytes), "text");
// encoding
assert_eq!(CP850.encode("text").unwrap(), bytes);
use yore::CodePage;
fn do_something(code_page: &dyn CodePage, bytes: &[u8]) {
println!("{}", code_page.decode(bytes).unwrap());
}
另外两个类似的库:
- lifthrasiir/rust-encoding: Character encoding support for Rust
- tats-u/rust-oem-cp: Rust library that handles OEM code pages (e.g. CP{437,737,850}) for single byte character sets
Rust 开发的 NPM 包搜索引擎
非常快速的 NPM 包搜索引擎:fast-npm-search.xyz | NPM packages search
From 日报小组 长琴
社区学习交流平台订阅:
评论区
写评论还没有评论