作为一名在软件领域工程师,在职业生涯的尽头能有幸接触到一部分硬件产品是我莫大的荣幸。秉承我一贯刨根问底,不搞清楚问题本质不罢休的作风和态度,结合基本的计算机知识加一部分FreeRTOS源码,开始了文档标题中的工作,这项工作带来的价值可以指导未来在嵌入式工程领域软件研发工作(人或事),深入而透彻,也能告诉你怎么通过硬件看清软件运行的本质;同时,也作为在嵌入式领域工程实践方面总结与回顾。
文档很枯燥,大部分内容是教科书上那些呈辞滥调的重复引用/解释,可参考的部分应该就剩下那份按部就班实现的工程样板代码。
我尽量用人类容易理解的熟语、类比加上大量的配图等来表达,如果您能坚持阅读下去那么我要恭喜您;如果您能阅读到参考工程的源码部分那么我佩服您;如果您能试着亲手撸一遍那么我要崇拜您;如果您能提出更优雅、跟妥当的实现方法或者能指出实现不恰当、错误的地方那么我要仰慕您;如果您能亲手移植一块芯片那么您对操作系统的调度机制应该已经非常通透了,接下来您要思考在多核心环境下如何实现调度,您也可以开始阅读Linux操作系统芯片部分、调度器部分代码了。
文档中存在描述不恰当或者错误地方,请您以参考实现为准,祝您阅读愉快!
目录
名词解释
这部分内容浏览一遍即可,当你往下阅读且无法准确理解的时候再回过来看看。这些名词解释来自维基百科,需要进一步了解请移步维基百科。
| 名词 | 说明 |
|---|---|
| ISA | (英语:Instruction Set Architecture,缩写为ISA),又称指令集或指令集体系,是计算机体系结构中与程序设计有关的部分,包含了基本数据类型,指令集,寄存器,寻址模式,存储体系,中断,异常处理以及外部I/O。指令集架构包含一系列的opcode即操作码(机器语言),以及由特定处理器执行的基本命令。常用的有x86、arm、risc-v、space |
| ISR | Interrupt Service Routines,中断服务程序,处理中断控制器发过来的请求,硬件回调软件 |
| 汇编指令 | 二进制指令的文本表示 |
| 编译器 | 一种计算机程序,它会将某种编程语言写成的源代码(原始语言)转换成另一种编程语言(目标语言)。典型过程:预处理/编译优化/汇编/链接,输出为ELF/PE文件 |
| 异常/中断 | 异常:硬件发生了某些紧急的事情(除0),需要通知到软件处理;中断:狭义上的异常,是一种硬件和软件的交互机制,程序在运行过程中被打断的意思,中断通常是紧急的所以正常的程序需要被打断,让CPU优先处理紧急事务 |
| IP | Intellectual Property 的缩写,翻译过来就是「知识产权」,是个法律概念;例如:ARM公司只出售IP和参考设计方案,不生产制造芯片 |
| SOC | SoC称为系统级芯片,也有称片上系统,意指它是一个产品,是一个有专用目标的集成电路,其中包含完整系统并有嵌入软件的全部内容。同时它又是一种技术,用以实现从确定系统功能开始,到软/硬件划分,并完成设计的整个过程。 |
| MCU | 微控制单元(Microcontroller Unit;MCU) ,又称单片微型计算机(Single Chip Microcomputer )或者单片机,是把中央处理器(Central Process Unit;CPU)的频率与规格做适当缩减,并将内存(memory)、计数器(Timer)、USB、A/D转换、UART、PLC、DMA等周边接口,甚至LCD驱动电路都整合在单一芯片上,形成芯片级的计算机,为不同的应用场合做不同组合控制。诸如手机、PC外围、遥控器,至汽车电子、工业上的步进马达、机器手臂的控制等,都可见到MCU的身影。 |
| DSP | 数字信号处理器(DSP)是一种专用的微处理器芯片,其架构针对数字信号处理的操作需求进行了优化。DSP是在MOS集成电路芯片上制造的。它们广泛用于音频信号处理、电信、数字图像处理、雷达、声纳和语音识别系统,以及常见的消费电子设备,如手机、磁盘驱动器和高清电视(HDTV)产品。DSP的目标通常是测量、过滤或压缩连续的真实模拟信号。大多数通用微处理器也可以成功执行数字信号处理算法,但可能无法实时连续地跟上这种处理。此外,专用DSP通常具有更好的功率效率,因此由于功耗限制,它们更适合移动电话等便携式设备。 DSP通常使用特殊的存储器架构,能够同时获取多个数据或指令。DSP通常还实现数据压缩技术,特别是离散余弦变换(DCT)是DSP中广泛使用的压缩技术。 |
| PLC | Programmable Logic Controller,可编程逻辑控制器是种专门为在工业环境下应用而设计的数字运算操作电子系统。它采用一种可编程的存储器,在其内部存储执行逻辑运算、顺序控制、定时、计数和算术运算等操作的指令,通过数字式或模拟式的输入输出来控制各种类型的机械设备或生产过程。 |
| RTOS | Real-time operating system, RTOS,又称即时操作系统,它会按照排序执行、管理系统资源,并为开发应用程序提供一致的基础。实时操作系统与一般的操作系统相比,最大的特色就是“实时性”,如果有一个任务需要执行,实时操作系统会马上(在较短时间内)执行该任务,不会有较长的延时。这种特性保证了各个任务的及时执行。常用的有:VxWorks、Nucleus、ThreadX、Windows CE、uCosii、RT-Thread、FreeRTOS、NuttX、LiteOS |
| 工具链 | 在开发软件过程中,一组工具链(英语:toolchain)是一系列用于制作软件程序的工具。这些工具一般一个接一个地运用,上一个工具的输出即是下一个工具的输入,因此得名。但工具链这个词汇也可指涉这些工具并无此相依执行的限制。通常一个软件开发的工具链由以下组成:编译器、链接器(将源代码/目标代码转换成可执行程序档)、库(提供与操作系统之间的界面)、调试器(用来测试、调试所产出的程序)。例如:GNU toolchain。 一个复杂的软件产品,例如影音电玩,就需要准备音效、音乐、3D模型与动画处理,处理这些资源的工具就需要组合这些元素成最终产品。 工具链与集成开发环境形成对照,分别代表了两种不同风格的软件开发环境。 |
| 链接脚本 | 链接脚本控制每次链接。这样的脚本是用链接器命令语言编写的。链接脚本的主要目的是描述如何将输入文件中的各个section(节)映射到输出文件中,并控制输出文件的内存布局。然而,在必要时,链接脚本也可以使用链接器命令指示链接器执行许多其他操作。下面的文档将讨论如何使用链接脚本及其命令。链接器总是使用链接脚本。如果你自己不提供,链接器将使用一个默认的链接脚本,这个脚本被编译进了链接器可执行文件中。你可以使用'--verbose '命令行选项来显示默认的链接脚本。某些命令行选项,如' -r '或' -N ',将影响默认链接脚本。你可以使用' -T '命令行选项提供自己的链接脚本。当这样做时,指定的链接脚本将替换默认的链接脚本。 |
| ELF/PE文件 | 可执行与可链接格式 (英语:Executable and Linkable Format,缩写 ELF,此前的写法是 Extensible Linking Format),常被称为 ELF格式,在计算中,是一种用于可执行文件、目标代码、共享库和核心转储(core dump)的标准文件格式;可移植性可执行文件(英语:Portable Executable,缩写为PE)是一种用于可执行文件、目标文件和动态链接库的文件格式,主要使用在32位和64位的Windows操作系统上 |
| 时钟脉冲信号 | 时脉信号(英语:Clock signal),计算机科学及相关领域用语。此信号在同步电路当中,扮演时脉的角色,并组成电路的电子组件。只有当同步信号到达时,相关的触发器才按输入信号改变输出状态,因此使得相关的电子组件得以同步运作。 |
| 控制器 | 控制单元(Control Unit),有时为CPU一部分,有时安装于CPU外部,负责指挥CPU工作。通过该设备的运行来控制其他设备的活动,也被视作有限状态自动机的一种。CPU的控制单元曾经只被当成暂时性的通路,其设计十分困难。 目前的控制单元多采用被包含于存储控制器的微程序加工制造。工作时由微型测序器选定微程序代码,其各字节即负责控制计算机的各个部分。诸如寄存器,算术逻辑单元,指令寄存器,总线,甚至芯片外部的输入输出均在其掌控之中。在当前的计算机中,各子系统分别拥有隶属于控制单元的控制器,由这些控制器监督各子系统工作。大多数计算机资源都由控制单元CU管理,其引导在CPU和其他设备间的指令流向,约翰·冯·诺伊曼将其归为冯·诺伊曼结构。在现代CPU的设计中,控制单元通常是CPU的一部分,其整体作用和操作自生产以来就不会改变。 |
| 下载工具/加载器 | 加载器(英语:Loader),又译为加载器、加载程序,是操作系统的一部分,负责程序的加载。它是程序执行中不可或缺的一个步骤,加载器会将程序置放在存储器中,让它开始执行。加载程序的步骤包括,读取可执行文件,将可执行文件的内容写入存储器中,之后开展其他所需的准备工作,准备让可执行文件运行。当加载完成之后,操作系统会将控制权交给加载的代码,让它开始运作。 |
| Bootloader/BIOS | 引导,或称引导程序,在计算机中是计算控制系统的一个初始化过程。引导过程可以是“硬引导”,如:开机通电后硬件诊断;也可以是“软引导”,此时会跳过开机自启。一些系统中软启动过程中,RAM可以不清零。软启动和硬启动都可以通过硬件发起,如按下电源开关;也可以通过软件命令来进行。当正常、有效的运行环境达到后,启动完成。 |
| 栈/中断/任务/线程栈 | 堆栈(英语:stack)又称为栈或堆叠,是计算机科学中的一种抽象资料类型,只允许在有序的线性资料集合的一端(称为堆栈顶端,英语:top)进行加入数据(英语:push)和移除数据(英语:pop)的运算。因而按照后进先出(LIFO, Last In First Out)的原理运作,堆栈常用一维数组或链表来实现。常与另一种有序的线性资料集合队列相提并论。用于中断ISR/任务/线程运行过程中保存CPU上下文、临时变量用的一块存储区域,通常由高地址向低地址寻址,符合LIFO的特征所以称为xx栈 |
| 堆/堆内存/堆分配 | 堆(英语:Heap)是计算机科学中的一种特别的完全二叉树。在计算机科学中, 动态内存分配(Dynamic memory allocation)又称为堆内存分配,是指计算机程序在运行期中分配使用内存。它可以当成是一种分配有限内存资源所有权的方法。 |
| SYSTICK | 系统节拍器,按一定频率产生中断信号,进而驱动现代操作系统运行 |
| 中断控制器 | 接收内外部中断请求,经过仲裁后调用中断服务程序 |
| Timer控制器 | 硬件计数器,实现tick比较,触发定时中断信号 |
| 寄存器 | (Register)是中央处理器/外设内用来暂存指令、数据和地址的存储器。寄存器的存贮容量有限,读写速度非常快。软件与硬件交换数据、指令的地方 |
| SP | Stack Pointer,堆栈指针,始终指向栈顶(可以是高地址也可以是低地址),通常由编译器设置,高级语言中不需要操作;存放的是内存地址 |
| PC | Program Counter,程序计数器,表示程序运行到了哪里,存放的是内存地址 |
| 状态寄存器 | CPU中除了SP、PC、LR、通用寄存器外,还有用于记录、配置CPU状态的一组寄存器,例如开/关中断、特殊寄存器备忘等 |
| 通用寄存器 | CPU提供给编译器临时保存指令、数据的地方,优化快速访问数据的目的 |
| OS内核 | |
| 上下文切换 | 现场保护、恢复 |
| SGI | Software Generated Interrupt,由软件触发的中断,中断源是软件 |
| 片内外设 | 集成在MCU/SOC内部的为片内外设,例如各种总线控制器、定时器、DMA、GPIO等 |
| 片外外设 | 一般通过PCB板连接到MUC/SOC的设备称为片外外设,例如:各种传感器,Flash芯片、显卡、内存芯片等 |
| 总线协议 | MCU/SOC与外设之间交换数据的协议,例如:PCIe、EIDE/ATA,SATA、SCSI、USB、IEEE 1394、UART、SPI、I2C、I2S、FMCS |
| 存储器 | 计算机存储器(英语:Computer memory)是一种利用半导体、磁性介质等技术制成的存储资料的电子设备。其电子电路中的资料以二进制方式存储,不同存储器产品中基本单元的名称也不一样。例如:SRAM、SDRAM、EPPROM、NorFlash、NandFlash,基本功能雷同,出于制造难道和成本分别有不同的应用场景 |
| 大端/小端 | 内存地址与字的映射关系,高低高低(高对低,大端)、高高低低(高对高低对低,小端),小端比较反人类,大端比较直观符合人类的思维模式 |
| MSB | Most Significant Byte,最高有效字节 |
| LSB | Least Significant Byte,最低有效字节 |
| HAL | 硬件抽象层的意思,位于操作系统内核与硬件电路之间的接口层,实现了芯片级外设的驱动(也就是如何操作MCU上的各种外设控制器内部的寄存器) |
软硬件生态

-
ISA
从图上看虽然ISA站在生态链的顶端,具有至高无上是权利和荣誉,但其实也很孤单,有多少曾今的王者纷纷倒下,例如:PA-RISC、PowerPC、Space、Alpha、Mips等,所以有种说法是: ISA不难设计,难的是软硬件生态建设。目前主流的ISA有x86、Arm、Risc-V(开源)。有了ISA,那么接下来就需要配套的软硬件环境了,
-
CPU核心&工具链&芯片
软件部分主要是设计、实现编译器、仿真器等工具链,硬件方面需要设计电路、制造芯片;有了前面两样东西那么后面基于这类芯片的电子产品也就可以上马了(深圳的华强北,特NB的地方),软件方面再接再厉按照增加一层就可以解决所有问题的套路继续往下生长
-
软件(操作系统、系统软件、中间件、应用软件)
操作系统、系统软件/工业软件、中间件、应用软件一层层往下累,有时候同一个概念或者本质问题被颠来倒去一次又一次拿出来卷,方法A、方法B、方法论N,看上去好像人类已经实现了计算机的升华,还是让我们回到计算机工作的本质上来;但是也不可否认开源的力量极大的推动了软件生态的发展;硬件产品越来越多,软件生态也越来越丰富,就这样整个生态就算走上正轨了,世界人民可以愉悦的消费着这些电子产品了。
-
Risc-V开源指令集
只是说你可以以免授权费的方式使用这份指令集设计、制造芯片,CPU核、芯片本身的设计、制造需要付出大量金钱(人、物等),这三个不是开源的,更不是免费的。如果Risc-V基金会能出一份CPU核参考设计就好了,那么大部分芯片设计、制造商加上部分片内外设就可以上市销售了,我想这样的生态应该更受欢迎,也更有利于Risc-V指令集架构的生态圈的建设。
计算机组成

约翰·冯·诺伊曼 数学家、计算机科学家、物理学家
上面这位大师告诉我们,计算机有五大基本部分组成,分别是输入设备、存储器、控制器、计算器、输出设备,如下图所示

神奇,就这5个部件怎么就能运行程序了呢?看看大师后面的机器“太土了”,现在的我们只要一块指甲大小的芯片就搞定了。
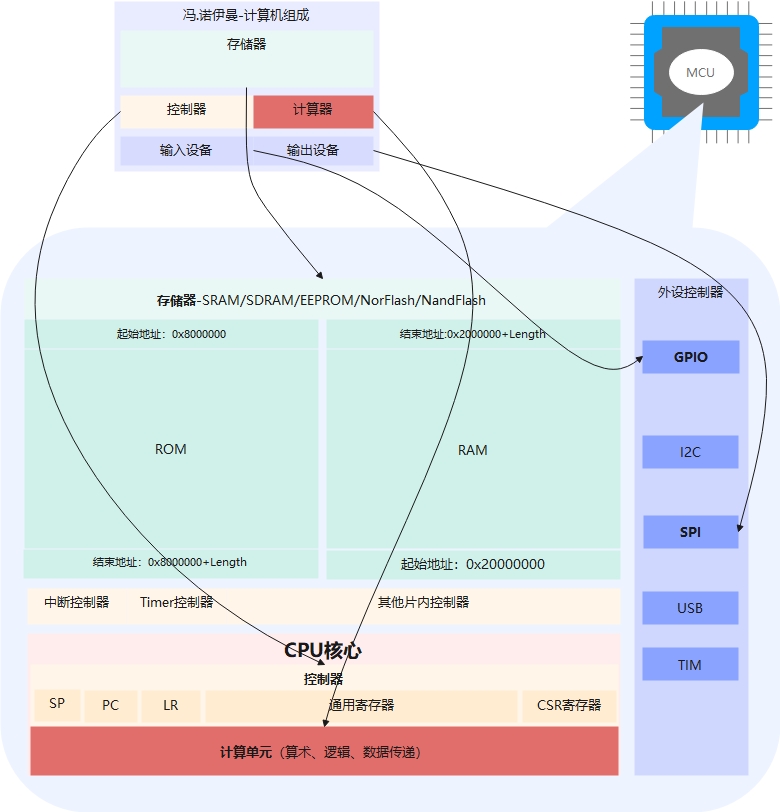
我们看到的MCU是一块芯片,就是单片计算机,因为它满足冯·诺伊曼的所有定义;芯片里面是另外一个大规模集成电路的世界。其中,CPU扮演了控制器和计算器的角色,SRAM/SDRAM/EEPROM/NorFlash/NandFlash等存储设备扮演了存储器的角色,外设控制器扮演了输入输出设备的角色,所以我们现在接触到的计算机都是存储计算模型,性能的瓶颈可能就发生在这种存储计算模型上。
存储器
MCU中为什么有这么多不同名称的存储器件呢?原因也很简单,还是成本、面积、功耗等几个方面的综合考量,来满足不同应用场景下对存储的需求。
外设控制器
GPIO、I2C、SPI啥滴是一种和MCU交换数据的控制器设备,俗称总线协议,约定了物理上的电路时序(PHY),USB之类还约定了软件传输协议方面的约定,这些总线类似PC上的PCIe总线差不多意思,总之是用来交换数据用的。为什么有这么多呢,针对不同应用场景下对速度、带宽、误码率、功耗、传输距离、制造复杂度等方面有针对性设计的产物。
CPU
有两类主要电路,一类是寄存器,一类是计算器,寄存器又分特定功能寄存器、通用寄存器和控制与状态寄存器,寄存器主要是用来保存、配置CPU,使它满足特定的功能,寄存器也是一种存储器,只是能存储的数据非常小,但是贼快,在CPU里一般跟CPU的字长一样大小,例如,8位的CPU寄存器一般也是8位,32位的CPU寄存器一般也是32位;特殊用途的寄存器有SP、PC、LR等,为了实现程序的流程控制以及临时变量的保存/释放等;通用寄存器通常给编译器使用,用于优化存取数据的操作;控制与状态寄存器,用于配置、打开、关闭、备忘特殊用户寄存器等CPU的某些功能和状态,例如,打开、关闭全局中断、把当前SP、PC临时保存到状态寄存器中等以便将来能undo操作;计算器就是一些算术运算、逻辑运算、数据传递的硬件电路,一般包括加法电路、乘法电路、除法电路、与、或、非、异或、取反等门电路。控制这些电路的就是一些开关器件,这些开关器件实现一会儿开一会儿关,那么从示波器里看上去一会儿高电平(1)一会儿低电平(0),能产品高低电平来代表1和0的电路称为数字电路。那么从软件工程师角度看的话可以理解为通过软编写的程序来控制电平的高高低低,进而满足某种数字化/信息化的需求。
了解了上面这些硬件,用来跑Helloworld应该足够了,那么我们的软件是如何运行在这些硬件上的呢?接着往下
软件是如何运行起来的
下面这张图是代码在存储器中的静态表示,以及如何从逻辑上划分存储区域;至于为什么要把存储器分区,我想是对存储器做个职责上的划分,大家各施其职不要越界,否则我给你脸色看,但是可以在领导、公司章程/规范(CPU、代码逻辑)的统一协调指挥下协作完成一项难以想象的任务。
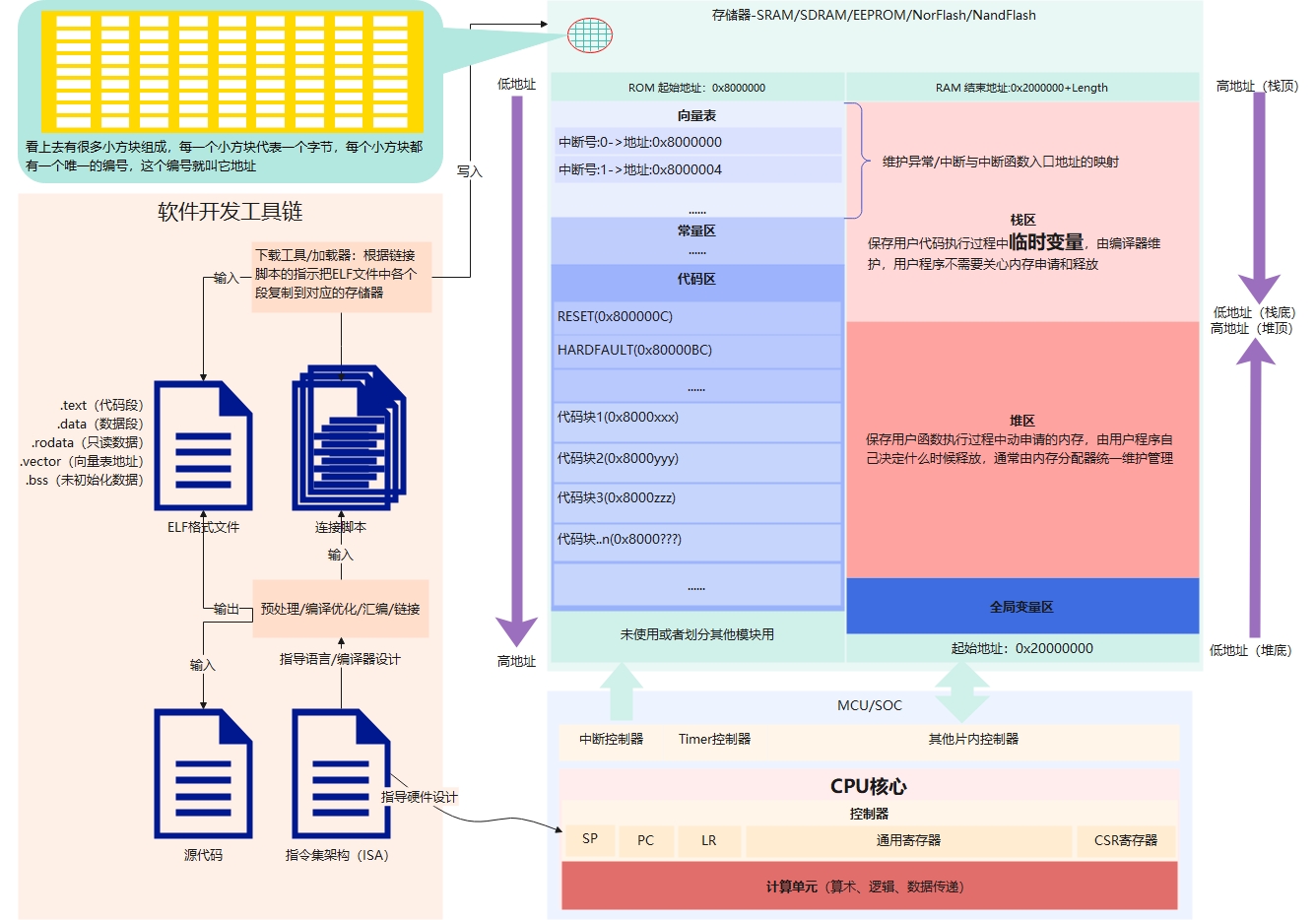
从左往右解释这张图
软件工具链
有了ISA那总要开发软件的吧,总不能看着ISA文档写代码吧,不妥不妥,开发效率低、烧脑、反人类、抽象表达能力差......,跟不上现代软件开发的节奏了,所有得有一套顺手的工具集才可以愉快的开发软件啊。
就是一套满足特定ISA软件开发的工具集。主要包括编译工具、调试工具、硬件虚拟化工具等。常见的开源编译器有gnu-gcc、gun-g++、clang/llvm、rustc等,商业的有vc、intel-c++、iar、armcc、borland-c++等,调试器有OpenOCD,GDB以及其他跟随IDEA一起发布的商业调试器,硬件虚拟化工具非大名鼎鼎的QEMU莫属了。
- 编译器
都知道是干嘛的。主要工作为预处理、编译/优化、汇编、链接,分别对应预处理器、编译优化器、汇编器、链接器。
- ELF/PE文件
链接器输出的就是这种类型的文件,对,它就是个文件,链接器的工作就是把编译器编译出来的很多文件,按照链接脚本的约定/指示组合成这个文件,这份文件有一定的格式要求,而且是可扩展的,以ELF文件为例,它由ELF头和各个段组成,段以.xxx来命名,典型的几个段是.text这个段放代码,将来会被加载器/下载器复制到ROM区,.data这段放已经初始化的数据/常量,将来会被复制到ROM区,.bss这个段放未初始化的数据/变量,将来会被复制到RAM全局变量区,.rodata这个段放的只读数据,将来可能被复制到ROM和RAM(看链接脚本是怎么指示的),.vector这个段放的是向量表,也就是异常/中断号与跳转地址的对应关系表,例如:中断号0->0x8000000,表示0号中断指向0x8000000这个地址,将来CPU如果发过来0号中断的话就先进这个地址拿指令,向量表的首地址通常是硬件复位中断的入口,也就是CPU上电后第一个寻址的地方,也是CPU上电后PC里的值,这个值是ISA约定或者芯片厂商约定的。
- 链接脚本
在嵌入式领域这个脚本显得特别重要,因为它决定了编译器编译出来的二进制代码是如何存储在存储器中的。如果你开发的软件是运行在带windows、linux、unix上的软件,那么你基本不会接触到它,因为链接器中有一份默认的公认的链接脚本。
示例,不用太纠结里面的语法,本质上就是一些给链接器用的符号/占位符以及代码、数据将来要复制到哪个存储区里
MEMORY
{
FLASH : ORIGIN = 0x08000000, LENGTH = 64K
RAM : ORIGIN = 0x20000000, LENGTH = 20K
}
PROVIDE(_stext = ORIGIN(REGION_TEXT));
PROVIDE(_stack_start = ORIGIN(REGION_STACK) + LENGTH(REGION_STACK));
PROVIDE(_max_hart_id = 0);
PROVIDE(_hart_stack_size = 2K);
PROVIDE(_heap_size = 0);
PROVIDE(UserSoft = DefaultHandler);
PROVIDE(SupervisorSoft = DefaultHandler);
PROVIDE(MachineSoft = DefaultHandler);
PROVIDE(UserTimer = DefaultHandler);
PROVIDE(SupervisorTimer = DefaultHandler);
PROVIDE(MachineTimer = DefaultHandler);
PROVIDE(UserExternal = DefaultHandler);
PROVIDE(SupervisorExternal = DefaultHandler);
PROVIDE(MachineExternal = DefaultHandler);
PROVIDE(DefaultHandler = DefaultInterruptHandler);
PROVIDE(ExceptionHandler = DefaultExceptionHandler);
PROVIDE(__pre_init = default_pre_init);
PROVIDE(_setup_interrupts = default_setup_interrupts);
PROVIDE(_mp_hook = default_mp_hook);
PROVIDE(_start_trap = default_start_trap);
SECTIONS
{
.text.dummy (NOLOAD) :
{
/* This section is intended to make _stext address work */
. = ABSOLUTE(_stext);
} > REGION_TEXT
.text _stext :
{
/* Put reset handler first in .text section so it ends up as the entry */
/* point of the program. */
KEEP(*(.init));
KEEP(*(.init.rust));
. = ALIGN(4);
(*(.trap));
(*(.trap.rust));
*(.text .text.*);
} > REGION_TEXT
.rodata : ALIGN(4)
{
*(.srodata .srodata.*);
*(.rodata .rodata.*);
/* 4-byte align the end (VMA) of this section.
This is required by LLD to ensure the LMA of the following .data
section will have the correct alignment. */
. = ALIGN(4);
} > REGION_RODATA
.data : ALIGN(4)
{
_sidata = LOADADDR(.data);
_sdata = .;
/* Must be called __global_pointer$ for linker relaxations to work. */
PROVIDE(__global_pointer$ = . + 0x800);
*(.sdata .sdata.* .sdata2 .sdata2.*);
*(.data .data.*);
. = ALIGN(4);
_edata = .;
} > REGION_DATA AT > REGION_RODATA
.bss (NOLOAD) :
{
_sbss = .;
*(.sbss .sbss.* .bss .bss.*);
. = ALIGN(4);
_ebss = .;
} > REGION_BSS
/* fictitious region that represents the memory available for the heap */
.heap (NOLOAD) :
{
_sheap = .;
. += _heap_size;
. = ALIGN(4);
_eheap = .;
} > REGION_HEAP
/* fictitious region that represents the memory available for the stack */
.stack (NOLOAD) :
{
_estack = .;
. = ABSOLUTE(_stack_start);
_sstack = .;
} > REGION_STACK
/* fake output .got section */
/* Dynamic relocations are unsupported. This section is only used to detect
relocatable code in the input files and raise an error if relocatable code
is found */
.got (INFO) :
{
KEEP(*(.got .got.*));
}
.eh_frame (INFO) : { KEEP(*(.eh_frame)) }
.eh_frame_hdr (INFO) : { *(.eh_frame_hdr) }
}
- 下载器/加载器
这个工具是根据链接脚本的指示,把ELF/PE文件中的代码、数据复制到特定的存储区域里。以上图为例,向量表被复制到ROM区起始地址处,常量数据被复制到ROM区的常量区,代码被复制到ROM区的代码区,全局变量被复制到RAM区的全局变量区,那么我们知道,代码、数据、变量等在编译完成后就已经确定了他们的长度,代码在运行过程中产生的临时变量和主动申请的内存被分别存放在RAM区的栈和堆区,栈的操作通常由编译器帮我们完成(一段代码的栈空间也是可以精确的计算出来的),剩下的堆区就需要我们自己管理了,为了能统一管理堆区,通常操作系统会实现堆内存管理模块,由这个模块负责堆内存的申请和回收。
CPU如何执行代码
当CPU上电后在晶振的驱动下,按照PC的指示开始寻址并执行指令,PC的初始值假设被设置为0x8000000,那么CPU先跳到这个地址,发现这个地址里的指令是跳转到REST那个中断服务函数的地址,然后就跳过去了开始执行REST代码块中的指令了,可能跑着跑着REST函数里又跳到了我们常见的main函数里,这个时候CPU的使用权就交到了用户程序了,main函数不返回一直运行下去,运行下去干嘛呢?等个中断信号执行下多任务调度算法就是接下来要干的事情,REST函数的生命周期也就到此结束了。
多任务调度
为什么要有多任务机制
如果没用多任务机制,在MCU中当然也是可以的,而且很多电子产品都没用RTOS把持,因为都是执行一些很简单的任务,所以一般用定时器+中断就可以是实现多个代码块之间跳转,操作系统对小应用来说太重了,不合适也没必要。
然而随着IOT业务的普及,RTOS慢慢开始吃香了,因为IOT设备上要干很多杂七杂八的事情,显然用定时器+中断会把人类搞成脑裂、疯癫状态,所以IOT业务场景下是很有必要使用RTOS的,以至于现在市面上的RTOS不下几十种,工作原理和实现机制都大同小异,本文档的参考实现中也参考了FreeRTOS的实现机制
工作机制
下面这张图是调度器代码、任务在存储器中的静态表示,以及CPU是如何在存储器里寻址并执行程序的

图中已经详细描述了,不再赘述,我想用老板、员工之间的对话来描述多任务工作机制应该更加容易理解
漫画
这副图主要用来表达多任务切换机制的核心思想,没用其他用意,如果您读到这段内容时感到对您有所冒犯或者不适,那么请你跳过这段内容直接往下看。
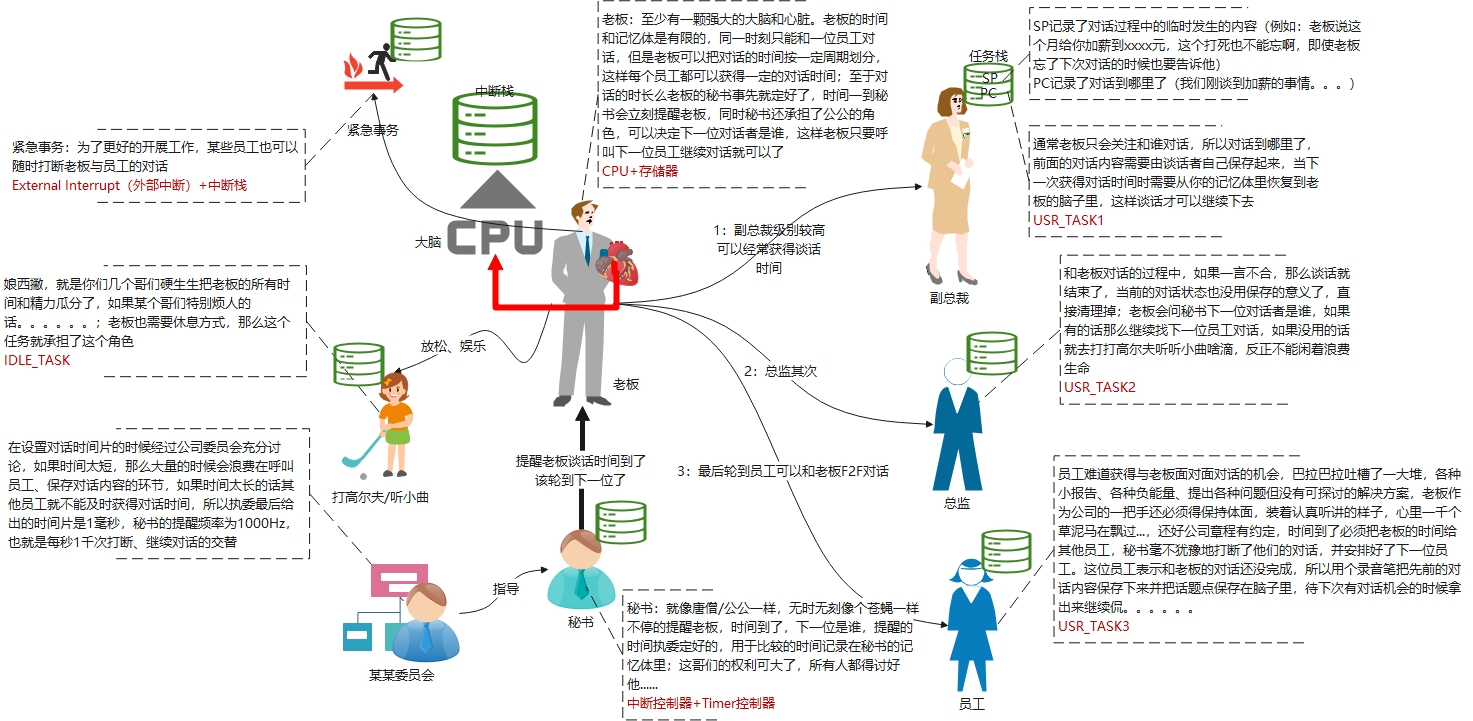
故事从老板与员工之间对话这件事开始了......
-
角色分工
- 某某委员会: 指定某种标准,具有至高无上的权利,代表指令集架构
- 老板: 对话任务执行者,具有强大的心脏和大脑以及用之不尽的精力,代表CPU
- 秘书: 他可以决定谁在什么时间和老板对话多长时间,受到某某委员会的约束,代表Timer控制器
- 紧急事务: 他们具有最高的优先级,可以不受秘书的约束直接找老板打小报告,代表外部高优先级中断
- 打高尔夫/听小曲: 老板没事了就找她去实现精神放松或者某种需求,代表空闲任务
- 副总裁: 是员工,但是组织内级别较高,有需要的话通常可以获得更多与老板对话的机会,代表高优先级任务
- 总监: 也是员工,级别比副总裁低一点,可以获得比副总裁少一点点的时间片,代表普通优先级任务
- 员工: 普通员工,级别最低,可以获得与老板对话的机会,这样显得整个组织是公平的,代表低优先级任务
-
对话开始了
- 一开始老板没用人对话,所以就去打打高尔夫听听小曲(在空闲任务那里放松呢)啥滴,愉悦地放松着自己
- 这时候秘书跑过来告诉老板,有几个员工有事找您,秘书表示,他们的时间和优先级我都已经按照某某委员会的要求安排妥当,不会占用您太多时间,到点我就让他们走,而且您也不需要关注对话到哪里或者对话了哪些内容,我会让他们自己记在脑子里(任务栈),您只要坐在办公室,我去叫他们就可以了,老板狂喜,那太好了;老板稍稍整理了下头、衬衣、领带啥滴,说:“那我们就开始吧”
- 秘书把副总裁叫到老板办公室,老板与副总裁的对话就这样开始了,某某总您找我谈啥(进入任务函数开始执行程序)......
- 1分钟后(假设TICK周期为1分钟)秘书跑到老板办公室,说:“某某总”您的时间到了,我们某某某委员会有规定,与老板的谈话时间最多1分钟,副总裁不乐意了,说我可是副总裁,好歹也是二把手,我有优先谈话权,而且我还没用和老板谈完,秘书一听对呀,某某委员会是有这么个规定,然后秘书就离开了(高优先级任务抢占)
- 1分30秒后,副总裁从老板办公室走出来,主动告诉秘书说我和老板的谈话结束了,您可以呼叫其他员工了(触发软中断,因为任务已经结束必须得切走)
- 秘书看了下登记表下一位优先级比较高的是总监(中断仲裁),于是秘书把总监叫到办公室开始与老板谈话......
- 突然,某个员工推开老板办公室的大门,找到老板说我有紧急事务要向您汇报(外部中断打断一般性任务),总监也很拎得清,默默地把谈话的内容、谈话到哪个环节给记录在了他的脑子里(压栈)便匆匆了离开了老板的办公室
- 老板处理完紧急事务,那个员工找秘书说我的事情办好了,你可以找下一位员工了(又触发了软中断)
- 秘书看到总监还等在那里,那意思是还没有谈完,因为总监的优先级比普通员工的优先级高而且还没有谈完,于是又叫总监去了老板办公室(高优先级抢占低优先级任务)......
- 过了45秒,总监从老板办公室出来了,意味着总监与老板的谈话结束了,总监告诉秘书可以呼叫下一位员工了(又触发了一次软中断)
- 终于轮到普通员工了,我等的花儿都谢了,巴拉巴拉巴拉......
- 1分钟时间到了,秘书分毫不差地跑到老板办公室,巴拉巴拉解释着某某委员会的规定,一名普通员工被请出了老板办公室,因为还有下一位普通员工还在门口候着(要公平),秘书让他在老板门口的沙发上坐一会儿等下一位员工谈话结束了再叫他,还不忘告诉他把刚才和老板谈话的内容和谈到哪里记在他的脑子里(压任务栈),因为老板要跟很多人谈话记不住那么多东西(职责明确且理由充分)
- 秘书叫来另外一位员工继续与老板谈话(因为他们都是普通员工,所以一次谈话时间就只能是1分钟,公平调度)......
- 1分钟到了,秘书重复着他的工作,把刚才等在门口的那位员工又请进了老板办公室
- ......秘书、老板重复着1分钟一次工作,终于所有员工谈话都结束了,老板表示我太难了,我要好好去放松一下,秘书心领神会,立马给老板安排了打高尔夫听小曲的任务(又回到了空闲任务),老板又可以愉悦的放松自我了
- 后面的内容不再重复,或者您有兴趣的话再编下去,反正日常工作事项就这些且没用经过某某委员会决策绝不能改
故事结束了,您GET到多任务切换的精髓了吗?如果激发起您亲手撸一遍多任务调度器代码的话我很愿意相信您真的看懂了这副漫画,虽然在撸代码的路途上还会碰到很多荆棘
时序
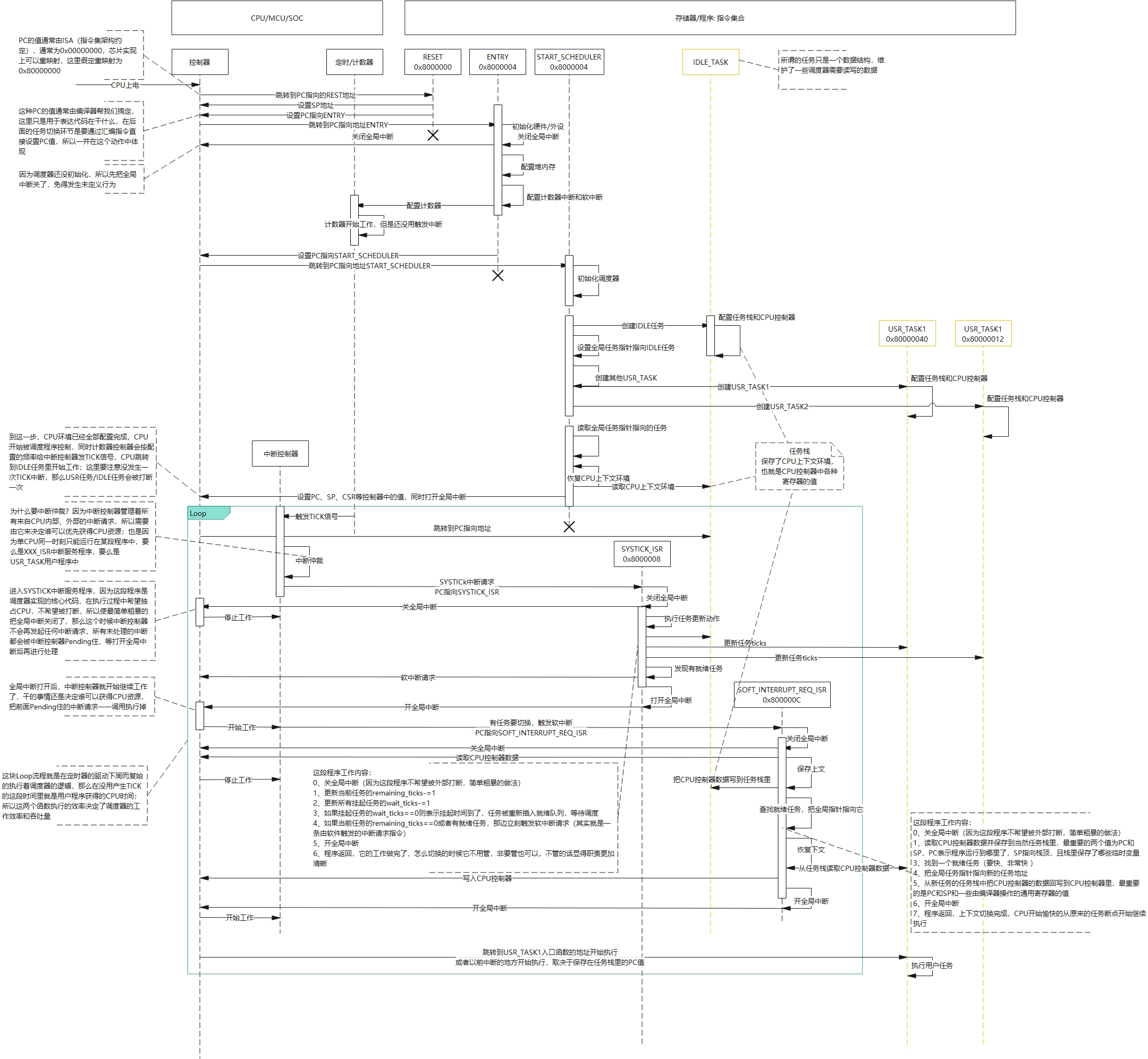
图中给出了详细的流程,不再赘述。
节拍器(定时器)

敲木鱼的和尚
和我们人类的心脏与大脑一样,CPU也需要外部晶振/振荡电路来带节奏,进而再去驱动我们的代码执行;那么我们的调度器同样也需要有人来带节奏,怎么驱动呢?Timer控制器出场了,Timer控制器里通常配置了一个固定值和一个可以被CPU累加的计数器,上电后CPU已经开始振荡,每振荡一次就会更新Timer控制器里的计数器,当Timer控制器发现计数器的值与那个固定值比较下,如果发现计数器大于等于那个固定值的话就给中断控制器发中断信号,表示定时时间到了,需要我们的调度器赶快去处理,中断控制器发现没用比Timer控制器更高优先级的或者Pending中的中断了,那么就告诉CPU赶紧去SYSTICK_ISR这个函数里执行,其他的任务先放一放;节拍器就干这个活,只要上电它就一直在工作。
如何配置那个固定值呢?固定值=CPU(RTC)频率/中断频率,例如:我们希望CPU每隔1毫秒调用一次SYSTICK_ISR函数,也就是1秒调用1000次=1000Hz,假如CPU(RTC)的频率是1800000Hz,那么这个固定值=1800000/1000=1800
佛祖早就看清了世界的本质,无欲无求。
时间片
字面意思理解就是把线性的时间轴给它分分段,每个段表示一个时间片,就像庙里的和尚敲木鱼,两次敲击之间的间隔时间就是时间片。主要用来给任务计时用,不要多个时间也不要少给时间,这样就实现了常说的公平调度,也就是把CPU公平的分配给每个任务,让所有任务都有机会执行
优先级
某些场景下,一些任务需要及时获得CPU时间来保证它在特定的时间内处理完任务,所以给任务增加一个优先级标志,调度器就可以按照高优先级先执行低优先级后执行的顺序分配CPU时间了,着就是常说的抢占式调度
关键代码说明
前面讲了很多调度原理和流程,我们来看看代码上是怎么实现的。代码是用rust写的(任何可以直接操作CPU寄存器的语言都可以实现,选择rust是因为核心库太好用了,常用数据结构都已经正确实现了),阅读的时候不用太关注那些跟语言相关的修饰符、语法之类,我尽量通过注释说明白代码实现的本质
任务定义
任务的本质上就是一个数据结构,里面定义了一些用于描述任务的关键属性,定义中只列出关键属性,其他属性请参考源码和语言相关的修饰符不用关注,理解任务定义的本质就行
pub struct Task {
//任务栈顶指针,很重要,任务首次启动或者上下文切换时要用到
pub(crate) sp: usize,
//任务栈空间,就是动态申请的一块内存空间,例如:4k字节,32为CPU的话usize=4字节,所以stack的长度为4k/4
pub(crate) stack: *mut usize,
//任务入口,真正执行任务逻辑的地方,任务首次运行PC值就是这个符号的地址,这个地址在任务初始化时被保存在上面的stack里
pub(crate) entry: Func,
//任务延时tick计数器,每tick一次减1,直到为0时表示延时结束,重新进入就绪队列等待下一次tick到来时调度
pub(crate) remaining_ticks: usize,
//任务ID,任务唯一的标识
pub(crate) id: u16,
//任务优先级,任务排序用,值越小优先级越高,调度器会优先调度
pub(crate) priority: u8,
//任务状态,记录任务当前的状态,典型的值有Ready(就绪)、Running(正在运行)、Suspended(挂起)、Blocked(阻塞)、Terminated(终止)
pub(crate) state: State,
}
任务初始化
当任务被创建时,需要对任务做一些初始化工作,关键内容是申请任务栈空间、配置CPU上下文环境并保存在任务栈里,为什么要保存在任务栈里呢,因为当任务首次运行的时候需要从任务栈里恢复出CPU的上下文,特别是PC、SP两个值,这样CPU才能正确的执任务代码
这块代码因为跟ISA相关所以是需要针对不同芯片实现,阅读这份代码需要你对RISC-V指令集架构中定义的寄存器有一定的了解,下面以GD32VF103芯片为例看看都干了写啥
/// 任务创建时为CPU准备好任务的现场,一共32个参数,占用36*4个字节
/// 包括入口函数、任务参加、返回地址、任务栈顶指针
/// 这段程序与汇编中实现的上文保存是同一个功能,唯一不同的是
/// 任务初始化时栈顶就是数组的尾地址,任务运行过程中栈顶的位置是不确定的,因为不知道任务函数里定义了多少变量,一个变量就要占一份栈空间
///
/// 0. 任务栈SP保存在任务sp字段,也是任务的第一个参数
/// 1. 任务入口函数就是当任务被第一次运行时的PC地址,保存在mepc寄存器中,
/// 2. 任务函数参数保存在a0寄存器中,寄存器编号为x10
/// 3. 任务返回地址保存在ra寄存器中,寄存器编号为x1
/// 4. 其他通用寄存器按约定的顺序保存在任务堆栈中即可
#[inline]
fn save_context(task: &mut Task) {
unsafe {
//任务栈指针移到栈顶,也就是数组的最后一个元素起始位置
let sp = task.stack.add(task.stack_size - 1);
/*
* 从任务栈顶开始压栈,压栈顺序如下,一共32个值,占用36*4字节任务栈空间
* mcause=0xb8000000,30:31为中断号(7),0:29为异常原因
* msubm(0x7c4)=0x40,自定义寄存器用于保存Core当前的Trap类型,以及进入Trap前的Trap类型。详见《Bumblebee内核指令架构手册》
* mepc=task.entry,出栈后mret指令会用mepc的值赋值给PC,这样就可以进入用户任务函数了
* mstatus=0x000000C80,mpp[11:12]和mpie[7]置位,mpp在机器模式==11,mpie=1当任务恢复后打开全局中断
* x31-x11 默认0
* x10(a0)=task.args,任务函数参数
* x9-x2 默认0
* x1(ra)=task_exit_error,任务返回地址
* x0 保留,任务栈sp指向这里
*/
sp.offset(-1).write_volatile(0xb8000000);
sp.offset(-2).write_volatile(0x40);
sp.offset(-3)
.write_volatile((task.entry as *const ()).addr());
sp.offset(-4).write_volatile(0x00000C80);
sp.offset(-26).write_volatile(task.args.addr());
sp.offset(-35)
.write_volatile((port::task_exit as *const ()).addr());
task.sp = sp.offset(-36).addr();
}
}
中断服务程序(调度器)
中断服务程序就实现了调度器关键代码,所以说现代操作系统是中断驱动的代码块
- 节拍器中断服务程序
这个函数被节拍器中断有节奏的调用,调用的频率取决于Timer控制器的配置,两次调用的间隔就是用户任务可以获得的最小时间片
/// 这个函数如果返回true,就说明有就绪任务,需要把当前任务切换掉,其实就是一条指令产生一个软中断,然后CPU会进入软中断服务程序里完成真正的切换,往下看下面一个函数就是
fn do_systick(&self) -> bool {
unsafe {
//从延时任务队列里扫描所有任务,并更新延时的remaining_ticks-=1,同时收集remaining_ticks==0的任务索引号
if let Some(delay) = &mut DELAY {
let readys: Vec<usize> = delay
.iter()
.enumerate()
.filter_map(|(i, task)| {
if let Some(task) = (*task).as_mut() {
if task.tick() {
Some(i)
} else {
None
}
} else {
None
}
})
.collect();
//这段代码就是把remaining_ticks==0(延时时间到了)的任务从延时队列里删除,并重新放到就绪队列里,submit_task这个函数会根据任务的状态值分发到不同的队列里
readys.iter().for_each(|i| {
if let Some(task) = delay.remove(*i) {
submit_task(task);
}
});
}
// 检查尾导零,是否有比当前任务相等或更高优先级的任务
// 如果想等优先级则时间片调度,否则就一直抢占着,直到任务主动挂起
// TODO 需改进 ARM CLZ指令计算前导零
let trailing_zero = READY_BITS.trailing_zeros();
trailing_zero < 16 && (trailing_zero + 1) <= self.current().priority as u32
}
}
- 软中断服务程序
这里实现了任务的真正切换,为什么要单独设计一个这样的服务函数呢?难道在节拍器中断服务程序里切不可以吗?答案是可以的,这样实现的目的是为了职责上的区别,节拍器就干节拍器的活,任务切换就干任务切换的活,大家分工明确。
什么时候触发任务切换呢?有一下几种情况:
- 节拍器周期到了且有就绪任务,就是上面节拍器中断服务程序里做的事情
- 任务函数里主动延时,例如调用了sleep函数,sleep函数里把当前任务状态置为Blocked,remaining_ticks=延时tick数
- 任务被挂起,例如:两个任务互斥(二值信号量/互斥锁),那么其中一个任务会被挂起
任务切换需要直接操作CPU寄存器,以RISC-V为例,汇编代码如下
// 保存上文宏
.macro SAVE_CONTEXT_SOFT_IRQ
// 开辟一块栈空间(栈操作快就是这个道理,加减下SP就行)
// SP向下偏移36个字,也就是任务被切走后的任务栈顶
addi sp, sp, -36 * 4
// 把x1写入sp偏移4字节的位置,0(sp)位置保留给x0寄存器,很等于0
sw x1, 1 * 4(sp) //ra(return address)//返回地址
// 保留x2,x3,x4栈空间,有点浪费~,但是看起来对齐比较舒服
sw x5, 5 * 4(sp) //t0(temporary)/lr(link register)t[x]临时寄存器
sw x6, 6 * 4(sp) //t1(temporary)
sw x7, 7 * 4(sp) //t2(temporary)
sw x8, 8 * 4(sp) //s0/fp(frame pointer) //s[x]保存寄存器/帧指针
sw x9, 9 * 4(sp) //s1(saved register)
sw x10, 10 * 4(sp) //a0(funcation arguments)/rtval(return value)//入参/返回值地址
sw x11, 11 * 4(sp) //a1(funcation arguments)/rtval(return value)//入参/返回值地址
sw x12, 12 * 4(sp) //a2(funcation arguments)//a[x]入参地址
sw x13, 13 * 4(sp) //a3(funcation arguments)
sw x14, 14 * 4(sp) //a4(funcation arguments)
sw x15, 15 * 4(sp) //a5(funcation arguments)
sw x16, 16 * 4(sp) //a6(funcation arguments)
sw x17, 17 * 4(sp) //a7(funcation arguments)
sw x18, 18 * 4(sp) //s2(saved register)
sw x19, 19 * 4(sp) //s3(saved register)
sw x20, 20 * 4(sp) //s4(saved register)
sw x21, 21 * 4(sp) //s5(saved register)
sw x22, 22 * 4(sp) //s6(saved register)
sw x23, 23 * 4(sp) //s7(saved register)
sw x24, 24 * 4(sp) //s8(saved register)
sw x25, 25 * 4(sp) //s9(saved register)
sw x26, 26 * 4(sp) //s10(saved register)
sw x27, 27 * 4(sp) //s11(saved register)
sw x28, 28 * 4(sp) //t3(temporary)
sw x29, 29 * 4(sp) //t4(temporary)
sw x30, 30 * 4(sp) //t5(temporary)
sw x31, 31 * 4(sp) //t6(temporary)
// CSR寄存器压栈,
csrr t0, mstatus
sw t0, 32 * 4(sp)
csrr t0, mepc // 当前任务的下一条指令的PC地址,也就是当前PC+4
sw t0, 33 * 4(sp) // PC地址入栈
csrr t0, 0x7C4 // Bumblebee内核
sw t0, 34 * 4(sp)
csrr t0, mcause
sw t0, 35 * 4(sp)
.endm
// 恢复下文,和上面的上文对齐即可
.macro REsw_CONTEXT_SOFT_IRQ
lw x1, 1 * 4(sp) // 任务返回地址
lw x5, 5 * 4(sp)
lw x6, 6 * 4(sp)
lw x7, 7 * 4(sp)
lw x8, 8 * 4(sp)
lw x9, 9 * 4(sp)
lw x10, 10 * 4(sp) // a0,任务参数
lw x11, 11 * 4(sp)
lw x12, 12 * 4(sp)
lw x13, 13 * 4(sp)
lw x14, 14 * 4(sp)
lw x15, 15 * 4(sp)
lw x16, 16 * 4(sp)
lw x17, 17 * 4(sp)
lw x18, 18 * 4(sp)
lw x19, 19 * 4(sp)
lw x20, 20 * 4(sp)
lw x21, 21 * 4(sp)
lw x22, 22 * 4(sp)
lw x23, 23 * 4(sp)
lw x24, 24 * 4(sp)
lw x25, 25 * 4(sp)
lw x26, 26 * 4(sp)
lw x27, 27 * 4(sp)
lw x28, 28 * 4(sp)
lw x29, 29 * 4(sp)
lw x30, 30 * 4(sp)
lw x31, 31 * 4(sp)
// CSR寄存器出栈
lw t0, 32 * 4(sp)
csrw mstatus, t0 // 恢复mstatus
lw t0, 33 * 4(sp)
csrw mepc, t0 // 恢复任务PC到mepc寄存器,最后由mret伪指令恢复到PC寄存器
lw t0, 34 * 4(sp)
csrw 0x7C4, t0 // Bumblebee内核自定义寄存器
lw t0, 35 * 4(sp)
csrw mcause, t0 // 恢复mcause
// SP指针上移,释放当前任务的栈空间,使SP指向任务被切换前的栈顶
addi sp, sp, 4 * 36
.endm
// 当前任务全局指针,在RUST代码中定义
.extern CURRENT_TASK_PTR
// IRQ entry point
.section .text.irq
.option push
.option norelax
.align 2
.option pop
.global _irq_handler
_irq_handler:
// 保存上文到任务堆栈
SAVE_CONTEXT_SOFT_IRQ
// 把当前任务的SP保存到任务栈
// CURRENT_TASK_PTR是当前任务的指针,指向了当前运行任务的地址,在RUST代码里维护
lw t0, CURRENT_TASK_PTR
sw sp, 0x0(t0)
// 切到中断栈
csrrw sp, mscratch, sp
// Bumblebee内核自定义寄存器实现了中断嵌套,跳转到中断向量表地址
// 执行这条指令后全局中断被打开mie=1,通过ra地址指向这条指令自己
// 实现了中断嵌套的功能,所以向量表里的定义的ISR服务函数不需要再
// 开关中断,中断服务程序不会被其他中断打断(除非发了不可屏蔽异常,
// 例如硬件错误),中断服务函数执行的CPU被独占着,所以中断服务函数
// 执行效率决定了多任务的响应能力、吞吐量、CPU利用率等关键指标
csrrw ra, 0x7ED, ra
// 退出0x7ED后关闭全局中断mie=0
// csrc表示清除CSR寄存器指定位的值
// 这里就表示清除mstatus寄存器mie位的值
csrc mstatus, 0x00000008
// 回到任务栈
csrrw sp, mscratch, sp
// 这个时候已经切换到新的任务,需要从新任务的栈空间恢复下文,栈顶地址就保存在任务第一个变量里
lw t0, CURRENT_TASK_PTR
// 这个任务栈地址要么是第一次创建的时候写入任务块的,要么是被切换走的时候写入任务块的
lw sp, 0x0(t0)
// 恢复下文到CPU寄存器
REsw_CONTEXT_SOFT_IRQ
// mepc值已经在上面恢复,执行这条伪指令将PC指向新任务断点处
// 同时mie从mpie恢复到中断前的状态,也就是要恢复到进入中断函数前的中断状态
mret
// 找到一个就绪任务把当前任务切出去
fn do_schedule(&self) {
unsafe {
//弹出一个就绪任务,把全局任务指向新的任务地址即可
let new = pop_ready();
if new != xworker.current() {
if let Some(new) = new.as_mut() {
if let Some(old) = xworker.execute(new).and_then(|item| item.as_mut()) {
//检查是否栈溢出
old.stack_overflow();
submit_task(old);
}
}
}
}
}
配置中断
在调度器启动前要先把Timer控制器和软中断(如果有的话)要先配置下,这样中断服务程序才可以正确的工作,本质上也是操作控制器里的寄存器,一般芯片厂商会提供HAL库,直接调用就可以了,一般都是样板代码,不用你再去啃芯片数据手册啥滴
/// 配置定时器、软中断、使能定时器中断和软中断
#[inline]
pub(crate) fn setup_intrrupt() {
unsafe {
//设置定时器中断
ECLIC::setup(
//定时器中断号
Interrupt::INT_TMR,
//上升沿触发
TriggerType::RisingEdge,
//中断等级
Level::L0,
//中断优先级
Priority::P0,
);
//设置软中断
ECLIC::setup(
//软中断号
Interrupt::INT_SFT,
//上升沿触发
TriggerType::RisingEdge,
//中断等级
Level::L0,
//中断优先级
Priority::P0,
);
//定时器中断使能
ECLIC::unmask(Interrupt::INT_TMR);
//软中断使能
ECLIC::unmask(Interrupt::INT_SFT);
}
}
启动第一个任务
上面的所有准备工作做完,到这里就可以开始启动调度器了
- 空闲任务
为了使CPU启动的时候有活干,先给CPU安排一个空的任务,这个任务里啥都不干就是一个死循环,当然也可以加一些CPU使用率统计工作,如果你使用过windows任务管理器,那么你应该可以看到一个idle的进程一直占用着大量的CPU,这个任务也类似。这个任务的特殊性还在于,如果没用其他就绪任务,那么调度器就切到这个任务上,把CPU让给它;这个任务和其他任务在数据结构上没用任何区别。
启动代码因为要从任务栈里恢复出CPU上下文,所以跟芯片相关且要直接操作CPU寄存器,还是以RISC-V为例,汇编代码如下
// 调度器启动时恢复第一个任务到CPU寄存器
//关全局中断
csrc mstatus, 0x00000008
// 获取link.x链接文件中_stack_start栈顶地址,因为这个函数不会返回,所以
// 当函数结束时还会留下一部分栈空间,这部分空间作为中断服务函数栈使用,以提
// 高内存利用率,同时,留512字节空间给启动函数,因为启动函数可能已经占用了
// 一部分堆栈空间,硬件启动栈空间是2k,剩下的1.5k作为中断栈使用
// 把栈顶地址保存到mscratch备用寄存器,当进入中断服务函数时可以拿出来给中断函数用
la t0, _stack_start
addi t0, t0, -512
csrw mscratch, t0
// 加载当前任务块地址
lw t0, CURRENT_TASK_PTR
// SP指向任务栈栈顶,任务块第一个变量就是指向任务栈顶
lw sp, 0x0(t0)
// 从栈顶出栈恢复CPU状态
// 通用寄存器出栈操作
lw x1, 1 * 4(sp) // 任务返回地址
lw x5, 5 * 4(sp)
lw x6, 6 * 4(sp)
lw x7, 7 * 4(sp)
lw x8, 8 * 4(sp)
lw x9, 9 * 4(sp)
lw x10, 10 * 4(sp) // a0,任务参数
lw x11, 11 * 4(sp)
lw x12, 12 * 4(sp)
lw x13, 13 * 4(sp)
lw x14, 14 * 4(sp)
lw x15, 15 * 4(sp)
lw x16, 16 * 4(sp)
lw x17, 17 * 4(sp)
lw x18, 18 * 4(sp)
lw x19, 19 * 4(sp)
lw x20, 20 * 4(sp)
lw x21, 21 * 4(sp)
lw x22, 22 * 4(sp)
lw x23, 23 * 4(sp)
lw x24, 24 * 4(sp)
lw x25, 25 * 4(sp)
lw x26, 26 * 4(sp)
lw x27, 27 * 4(sp)
lw x28, 28 * 4(sp)
lw x29, 29 * 4(sp)
lw x30, 30 * 4(sp)
lw x31, 31 * 4(sp)
// CSR寄存器出栈
lw t0, 32 * 4(sp)
csrw mstatus, t0 // 恢复mstatus,当mret时mie=mpie,即打开全局中断
lw t0, 33 * 4(sp)
csrw mepc, t0 // 任务入口函数在这里,也是PC地址
lw t0, 34 * 4(sp)
csrw 0x7c4, t0 // 自定义寄存器
lw t0, 35 * 4(sp)
csrw mcause, t0 // 保存异常代码
// 释放栈空间,栈指针上移,
// 任务块栈顶指针的值还是保持在原来的地方,这里更
// 不更新无所谓,因为任务已经在运行,当被切换掉时会被更新掉
addi sp, sp, 4 * 36
// 这条伪指令CPU就开始执行任务函数了,使PC=mepc,mie=mpie
mret
您在阅读汇编代码的时候也不用太抵触,实现大部分业务逻辑的时候我们很少用汇编,因为太难表达了,人类没用经过专门的训练很难像机器一样工作,反人类,这个事情交给编译器去完成就行,那么这里的汇编指令其实没用几条,而且功能也很单一,干的事情也就剩下操作下栈指针偏移量,设置下PC和SP以及CSR寄存器的值,从全局任务指针变量里读出任务的地址(直接读内存地址),汇编代码结束的时候CPU就会从新的PC值开始执行了
通过以上汇编代码中对栈指针的操作其实就是内存地址的加减操作,简单且干脆,所以栈操作通常非常快就是这个原因
调度器执行效率直接决定了操作系统的工作效率以及吞吐量,这部分代码也是很多RTOS长期优化的地方
IPC&SYNC
光有多任务调度是很难满足真实业务需求的,特别是任务间的通信机制,共享数据的竞争等
二值信号量&互斥量
所谓二值信号量就是一个值它有两个状态,一个状态标识有信号,一个状态表示没用信号了,当有信号的时候那么任务就可以持有这个信号量,那么另外一个任务就不能获得信号量,当不能获得悉信号量的时候就把自己给挂起,然后触发一个软中断就可以了,当持有信号量的任务释放信号量的时候通知下刚才那个挂起的任务并把那个任务重新放到就绪队列里就可以了,当下一个tick中断到来时调度器会调度这个就绪任务,那么这个时候这个任务就可以持有信号量了;
二值信号量通常用在两个互斥任务之间协同完成某项工作,它与互斥量的唯一区别是,互斥量是的信号由任务自身获取、释放。
pub struct Notifier {
blocker: Rc<usize>, //当前挂起者任务指针
signal: Rc<AtomicBool>, //信号标记,智能指针包下,防止move过程中地址里的值被转移到其他任务栈
}
impl Notifier {
pub fn new() -> Self {
Self {
blocker: Rc::new(0),
signal: Rc::new(AtomicBool::new(false)),
}
}
}
unsafe impl Send for Notifier {}
impl Notifier {
#[inline]
unsafe fn block(&self) {
let task = xworker.current();
let addr = (task as *mut Task).addr();
core::ptr::write_volatile(self.blocker.as_ref() as *const _ as *mut usize, addr);
task.block();
}
#[inline]
unsafe fn wakeup(&self) {
let blocker = core::ptr::read_volatile(self.blocker.as_ref());
if blocker != 0 {
let blocker = &mut *(blocker as *mut Task);
core::ptr::write_volatile(self.blocker.as_ref() as *const _ as *mut usize, 0);
blocker.wakeup();
}
}
/// 产生一个信号,如果信号写入
/// 成功则唤醒挂起的任务否则报错
pub fn notify_isr(&self) -> nb::Result<(), Error> {
match self
.signal
.compare_exchange(false, true, Ordering::SeqCst, Ordering::SeqCst)
{
Ok(_) => unsafe {
self.wakeup();
Ok(())
},
Err(_) => Err(nb::Error::WouldBlock),
}
}
/// 产生一个信号,如果信号写入
/// 成功则唤醒挂起的任务,如果
/// 信号写入失败则挂起自己
pub fn notify(&self) {
loop {
match self
.signal
.compare_exchange(false, true, Ordering::SeqCst, Ordering::SeqCst)
{
Ok(_) => {
sync::free(|_| unsafe {
self.wakeup();
});
break;
}
Err(_) => {
sync::free(|_| unsafe {
self.block();
});
yield_now();
}
}
}
}
/// 等待一个信号
/// 如果有信号则唤醒通知者,否则挂起自己
pub fn wait(&self) {
loop {
match self
.signal
.compare_exchange(true, false, Ordering::SeqCst, Ordering::SeqCst)
{
Ok(_) => {
sync::free(|_cs| unsafe {
self.wakeup();
});
break;
}
Err(_) => {
sync::free(|_cs| unsafe {
self.block();
});
yield_now();
}
}
}
}
}
多值信号量
多值信号量,从字面意思理解就是信号量有多个值,实现上其实就是维护一个计数器;应用场景为多个任务之间相互通知,可以用来实现MPMC(多生产者多消费者)队列
/// 信号量
/// 设计思想是维护两个任务挂起队列
/// 当信号量为零时挂起当前任务到挂起队列
/// 当信号量大于零时从挂起队列弹出任务交给调度器
pub struct Semaphore {
waiters: Rc<RefCell<TaskQueue>>,
notifiers: Rc<RefCell<TaskQueue>>,
signal: Rc<AtomicUsize>, //信号量
max_value: usize,
}
impl Semaphore {
pub fn new() -> Self {
Self::with_signal(0)
}
pub fn with_signal(signal: usize) -> Self {
Self::with_signal_max_value(signal, usize::MAX)
}
pub fn with_max_value(max_value: usize) -> Self {
Self::with_signal_max_value(0, max_value)
}
pub fn with_signal_max_value(signal: usize, max_value: usize) -> Self {
Self {
waiters: Rc::new(RefCell::new(TaskQueue::new())),
notifiers: Rc::new(RefCell::new(TaskQueue::new())),
signal: Rc::new(AtomicUsize::new(signal)),
max_value: max_value,
}
}
}
impl Semaphore {
/// 发送信号
/// 可以在中断服务中使用
///
pub fn post_isr(&self) -> nb::Result<(), Error> {
if self.signal.fetch_add(1, Ordering::SeqCst) <= self.max_value {
unsafe {
if let Some(waiter) = self.waiters.borrow_mut().pop_front() {
if let Some(waiter) = waiter.as_mut() {
waiter.wakeup();
}
}
};
Ok(())
} else {
Err(nb::Error::Other(Error::SemaphoreFull))
}
}
/// 发送信号
/// 不能在中断服务中使用
pub fn post(&self) {
loop {
if self.signal.fetch_add(1, Ordering::SeqCst) <= self.max_value {
sync::free(|_| unsafe {
if let Some(waiter) = self.waiters.borrow_mut().pop_front() {
if let Some(waiter) = waiter.as_mut() {
waiter.wakeup();
}
}
});
break;
} else {
sync::free(|_| {
let task = xworker.current();
self.notifiers.borrow_mut().push_back(task as *mut Task);
task.block();
});
yield_now();
}
}
}
/// 等待一个信号量
/// 禁止在中断服务中调用
/// 注意:不要同时使用post_isr和post,不然可能会错误的唤醒poster
pub fn wait(&self) {
loop {
match self
.signal
.fetch_update(Ordering::SeqCst, Ordering::SeqCst, |signal| {
if signal == 0 {
None
} else {
Some(signal - 1)
}
}) {
Ok(_) => {
sync::free(|_| unsafe {
if let Some(poster) = self.notifiers.borrow_mut().pop_front() {
if let Some(poster) = poster.as_mut() {
poster.wakeup();
}
}
});
break;
}
Err(_) => {
sync::free(|_| {
let task = xworker.current();
self.waiters.borrow_mut().push_back(task);
task.block();
});
yield_now();
}
}
}
}
}
队列
如果信号量只能用来产生信号,那么队列同时可以用来传递数据,多个任务间交换数据是很常见的业务场景。实现的思理就是多种信号量加上数组
//! 多生产者,多消费者队列
//! 中断服务中使用请用xxx_isr方法
pub struct Queue<T> {
list: Rc<RefCell<VecDeque<T>>>,
sem: Semaphore,
}
impl<T> Queue<T> {
pub fn new() -> Self {
Self {
list: Rc::new(RefCell::new(VecDeque::new())),
sem: Semaphore::new(),
}
}
pub fn with_capacity(capacity: usize) -> Self {
Self {
list: Rc::new(RefCell::new(VecDeque::new())),
sem: Semaphore::with_max_value(capacity),
}
}
}
impl<T> Queue<T> {
pub fn pop_front(&self) -> Option<T> {
self.sem.wait();
sync::free(|_| self.list.borrow_mut().pop_front())
}
pub fn pop_back(&self) -> Option<T> {
self.sem.wait();
sync::free(|_| self.list.borrow_mut().pop_back())
}
pub fn push_front(&self, item: T) {
sync::free(|_| {
self.list.borrow_mut().push_front(item);
});
self.sem.post();
}
pub fn push_back(&self, item: T) {
sync::free(|_| {
self.list.borrow_mut().push_back(item);
});
self.sem.post();
}
pub fn push_front_isr(&self, item: T) -> nb::Result<(), sync::Error> {
self.list.borrow_mut().push_front(item);
match self.sem.post_isr() {
Ok(_) => Ok(()),
Err(_) => Err(nb::Error::Other(sync::Error::QueueFull)),
}
}
pub fn push_back_isr(&self, item: T) -> nb::Result<(), sync::Error> {
self.list.borrow_mut().push_back(item);
match self.sem.post_isr() {
Ok(_) => Ok(()),
Err(_) => Err(nb::Error::Other(sync::Error::QueueFull)),
}
}
}
软件定时器
定时器太有用了,可以用来做计时器,计数器等待,可以按固定周期执行也可以一次性执行,而且干的事情也及其轻量级(不允许在定时器里干特别多的事情,否则会影响其他定时任务的执行),看上去任务也可以干这个事情,但是任务太重了不是吗,我们用一个任务去维护所有的定时任务就可以了
// 大顶堆保存定时任务
static mut HEAP: Option<BinaryHeap<Box<TimerInner>>> = None;
// 就绪任务保存在数组里
static mut READY: Option<VecDeque<Box<TimerInner>>> = None;
static mut TIMER_TASK: *mut Task = core::ptr::null_mut();
pub(crate) fn start_timer_task() {
log::info!("start_timer_task");
unsafe {
if HEAP.is_none() {
HEAP = Some(BinaryHeap::new());
READY = Some(VecDeque::new());
}
let task = Task::new(
TIMER_TASK_NAME,
TIMER_STACK_SIZE_WORD,
1,
timer_task,
core::ptr::null_mut(),
);
if let Some(task) = task.as_mut() {
task.state = State::Suspended;
}
core::ptr::replace(&mut TIMER_TASK, task);
}
fn timer_task(_args: *mut c_void) {
loop {
sync::free(|_cs| unsafe {
if let Some(q) = &mut READY {
loop {
if let Some(mut t) = q.pop_front() {
(t.entry)(t.args);
if t.period > 0 {
t.next_tick = time::tick() + t.period as u64;
submit(t);
}
} else {
break;
}
}
}
let task = xworker.current();
task.block();
});
}
}
}
/// 扫描堆顶是否有超时定时任务
/// 有则唤醒工作任务,触发软中断
#[inline]
pub(crate) fn do_tick(ticks: u64) {
unsafe {
if let Some(heap) = &mut HEAP {
let mut ready = false;
if let Some(timer) = heap.peek() {
if ticks >= timer.next_tick {
ready = true;
}
}
if ready {
if let Some(timer) = heap.pop() {
if let Some(q) = &mut READY {
q.push_back(timer);
} else {
let mut q = VecDeque::new();
q.push_back(timer);
READY = Some(q)
}
}
if let Some(task) = TIMER_TASK.as_mut() {
task.wakeup();
}
yield_now();
}
}
}
}
#[repr(C)]
#[derive(Debug, Eq, Clone)]
struct TimerInner {
entry: Func, //入口函数
args: *mut c_void, //参数
period: usize, //周期
next_tick: u64, //下次触发时间
}
impl Drop for TimerInner {
fn drop(&mut self) {
if self.period > 0 {
unsafe {
let _ = Box::from_raw(self.args as *mut Box<dyn Fn()>);
}
}
}
}
impl TimerInner {
fn after<F: FnOnce() + Send + 'static>(ms: usize, f: F) {
fn entry(args: *mut c_void) {
unsafe {
let b = Box::from_raw(args as *mut Box<dyn FnOnce()>);
b();
}
}
let f: Box<Box<dyn FnOnce() + Send + 'static>> = Box::new(Box::new(f));
let args = &*f as *const _ as *mut c_void;
let after = time::ms2ticks(ms);
let timer = Box::new(Self {
entry: entry,
args: args,
period: 0,
next_tick: time::tick() + after as u64,
});
core::mem::forget(f);
sync::free(|_| unsafe { submit(timer) });
}
fn period<F: Fn() + Send + 'static>(period_ms: usize, f: F) -> usize {
fn entry(args: *mut c_void) {
unsafe {
let b = Box::from_raw(args as *mut Box<dyn Fn()>);
b();
core::mem::forget(b);
}
}
let f: Box<Box<dyn Fn() + Send + 'static>> = Box::new(Box::new(f));
let args = &*f as *const _ as *mut c_void;
let period = time::ms2ticks(period_ms);
let timer = Box::new(Self {
entry,
args,
period,
next_tick: time::tick() + period as u64,
});
core::mem::forget(f);
let addr = timer.args.addr();
sync::free(|_| unsafe { submit(timer) });
addr
}
}
unsafe fn submit(timer: Box<TimerInner>) {
if let Some(heap) = &mut HEAP {
heap.push(timer);
} else {
let mut heap = BinaryHeap::new();
heap.push(timer);
HEAP = Some(heap);
}
}
pub struct Timer(usize);
impl Timer {
pub fn after<F: FnOnce() + Send + 'static>(ms: usize, f: F) {
TimerInner::after(ms, f)
}
pub fn period<F: Fn() + Send + 'static>(period_ms: usize, f: F) -> Timer {
Timer(TimerInner::period(period_ms, f))
}
}
芯片移植
什么是移植,所谓的移植都干了些啥?按我的理解是驱动CPU工作的一段驱动/桥接代码,操作系统通过合理的设计,定义出一层抽象接口,那么某个芯片只要实现了这层接口就可以驱动操作系统工作,是软件工程设计模式中桥接模式的典型应用。
通常这段移植代码由芯片供应商实现,但是现实又很残酷,RTOS太碎片化了,芯片厂商没有多少的资源放在移植代码这件事情上,所以通常会给出一份常用RTOS的移植代码、Hal库和芯片数据手册,剩下的事情由下游厂商自行完成。
移植层接口定义
/// 移植层接口定义
pub trait Portable {
/// 完全内存屏障
/// 保证在屏障之前的任何存储操作先于屏障之后的代码执行。
fn barrier();
/// 临界区保护函数
fn free<F, R>(f: F) -> R
where
F: FnOnce(&CriticalSection) -> R;
/// 开全局中断
fn enable_interrupt();
/// 关全局中断
fn disable_interrupt();
/// 启动调度器
fn start_scheduler() -> !;
/// 软中断
fn irq();
/// 关闭软中断
fn disable_irq();
/// 获取systick
fn systick() -> u64;
/// 硬件延时,单位us
fn delay_us(us: u64);
/// 保存任务环境到任务栈
fn save_context(task: &mut Task);
}
RISC-V
前面讲了一大堆工作原理和流程,我们来看看GD32VF103芯片上怎么去实现定义的抽象层函数
- 中断服务程序部分
// 导入汇编代码
global_asm!(include_str!("port.S"));
/**导出中断服务函数,导出名称必须与port.S汇编代码中定义的一致**/
/// riscv规定,进入中断函数前,全局中断被硬件自动关闭,mpie=mie,mie=0
/// 从中断函数退出后,mie被mpie恢复,恢复到中断前的中断状态
/// 注意,退出中断服务不是指退出当前这个函数,而是在汇编代码实现的_irq_handler函数
/// 定时中断服务函数,驱动任务调度,当有任务需求切换时触发软中断即可,
/// 任务切换由软中断服务函数实现,gd32里使用自定义寄存器(0x7ED)巧
/// 妙的实现了中断嵌套,工作职责清晰。
/// 当进入中断函数时SP已经在port.S汇编代码中切换到了中断栈,中断栈只
/// 有1.5k,所以函数不要嵌套太深,特别要防止递归调用
#[export_name = "INT_TMR"]
unsafe extern "C" fn mtimer_irq_isr() {
//isr_sprintln!("mtimer_irq_isr");
//设置下一次中断时间
super::reset_systick();
if scheduler::systick() {
super::Gd32vf103Porting::irq();
}
}
/// 软中断服务函数,这里只要实现任务切换即可,上下文保存
/// 在port.S汇编代码里实现,这个函数工作在中断栈,同样
/// 要注意函数嵌套和递归调用
///
/// 任务切换原理
/// 1.保存当然cpu状态到当前任务栈(port.S里实现)
/// 2.保存任务当前栈顶地址到任务块第一个变量里,将来任务被切回来时要用到
/// 3.关软中断,防止被再一次触发;根据调度算法选择合适的任务,把全局任务指针指向新的任务
/// 4.从新任务恢复cpu状态在port.S里实现)
#[export_name = "INT_SFT"]
unsafe extern "C" fn soft_irq_isr() {
//关闭软中断
super::Gd32vf103Porting::disable_irq();
scheduler::schedule();
}
/// 所有任务的退出函数,调用exit函数即可
pub(crate) unsafe extern "C" fn task_exit() {
scheduler::exit_current_task();
}
- 移植层实现部分
/// gd32芯片移植层实现
pub struct Gd32vf103Porting;
impl Portable for Gd32vf103Porting {
/// 完全内存屏障
/// 保证在屏障之前的任何存储操作先于屏障之后的代码执行。
#[inline]
fn barrier() {
unsafe {
riscv::asm::sfence_vma_all();
}
}
/// 临界区保护
#[inline]
fn free<F, R>(f: F) -> R
where
F: FnOnce(&CriticalSection) -> R,
{
riscv::interrupt::free(f)
}
/// 开全局中断
#[inline]
fn enable_interrupt() {
unsafe {
riscv::interrupt::enable();
}
}
/// 关全局中断
#[inline]
fn disable_interrupt() {
unsafe {
riscv::interrupt::disable();
}
}
/// 启动调度器
/// 1. 配置定时器中断、软中断触发类型和优先级
/// 2、把第一个任务恢复到CPU中,内联汇编实现
fn start_scheduler() -> ! {
reset_systick();
//配置中断,这个函数就是定时中断和软中断使能
setup_intrrupt();
log::info!("Start scheduler");
//从任务栈恢复CPU状态,汇编实现
unsafe { asm!(include_str!("restore_ctx.S")) };
//这个函数不会返回,因为在汇编中最后一条指令是mret,而不是ret
//mret把mepc更新到PC,而ret把ra更新到PC
panic!("~!@#$%^&*()_");
}
/// 软中断
/// 当软中断被打开时触发软中断,直到软中断或者全局中断关闭为止
#[inline]
fn irq() {
let ptr = (TIMER_CTRL_ADDR + TIMER_MSIP) as *mut u8;
unsafe {
ptr.write_volatile(*ptr | 0x01);
}
}
/// 关闭软中断
#[inline]
fn disable_irq() {
let ptr = (TIMER_CTRL_ADDR + TIMER_MSIP) as *mut u8;
unsafe {
ptr.write_volatile(*ptr & !0x01);
}
}
/// 读取计数器寄存器的值,保存了从CPU工作开始到现在的rtc tick数
/// mtime是个可读写且单调递增寄存器,通常不要去设置它,让它一直保存单调递增即可
/// 有两个32位寄存器组成,共64位,所以在已知的生命周期内不用考虑这个值的溢出
#[inline]
fn systick() -> u64 {
loop {
let hi = unsafe { *((TIMER_CTRL_ADDR + TIMER_MTIME + 4) as *mut u32) };
let lo = unsafe { *((TIMER_CTRL_ADDR + TIMER_MTIME) as *mut u32) };
if hi == unsafe { *((TIMER_CTRL_ADDR + TIMER_MTIME + 4) as *mut u32) } {
return (hi as u64) << 32 | (lo as u64);
}
}
}
/// 重新设置mtimecmp寄存器
/// mtimecmp=TICKS+mtime的值,当mtimecmp的值大于等于mtime时触发定时器中断
/// 硬件延时,单位us
#[inline]
fn delay_us(us: u64) {
let t0 = riscv::register::mcycle::read64();
let clock = (us * (CPU_CLOCK_HZ as u64)) / 1_000_000;
while riscv::register::mcycle::read64().wrapping_sub(t0) <= clock {}
}
/// 任务创建时为CPU准备好任务的现场,一共32个参数,占用36*4个字节
/// 包括入口函数、任务参加、返回地址、任务栈顶指针
/// 这段程序与汇编中实现的上文保存是同一个功能,唯一不同的是
/// 任务初始化时栈顶就是数组的尾地址,任务运行过程中栈顶的位置是不确定的
///
/// 0. 任务栈SP保存在任务sp字段,也是任务的第一个参数
/// 1. 任务入口函数就是当任务被第一次运行时的PC地址,保存在mepc寄存器中,
/// 2. 任务函数参数保存在a0寄存器中,寄存器编号为x10
/// 3. 任务返回地址保存在ra寄存器中,寄存器编号为x1
/// 4. 其他通用寄存器按约定的顺序保存在任务堆栈中即可
#[inline]
fn save_context(task: &mut Task) {
unsafe {
//任务栈指针移到栈顶,也就是数组的最后一个元素起始位置
let sp = task.stack.add(task.stack_size - 1);
// 需要8字节对齐,参考FreeRTOS,说是为了双精度浮点运算,还没搞明白,暂且注释掉
//sp = ((sp as usize) & !(0x0007)) as *mut usize;
/*
* 从任务栈顶开始压栈,压栈顺序如下,一共32个值,占用36*4字节任务栈空间
* mcause=0xb8000000,30:31为中断号(7),0:29为异常原因
* msubm(0x7c4)=0x40,自定义寄存器用于保存Core当前的Trap类型,以及进入Trap前的Trap类型。详见《Bumblebee内核指令架构手册》
* mepc=task.entry,出栈后mret指令会用mepc的值赋值给PC,这样就可以进入用户任务函数了
* mstatus=0x000000C80,mpp[11:12]和mpie[7]置位,mpp在机器模式==11,mpie=1当任务恢复后打开全局中断
* x31-x11 默认0
* x10(a0)=task.args,任务函数参数
* x9-x2 默认0
* x1(ra)=task_exit_error,任务返回地址
* x0 保留,任务栈sp指向这里
*/
sp.offset(-1).write_volatile(0xb8000000);
sp.offset(-2).write_volatile(0x40);
sp.offset(-3)
.write_volatile((task.entry as *const ()).addr());
sp.offset(-4).write_volatile(0x00000C80);
sp.offset(-26).write_volatile(task.args.addr());
sp.offset(-35)
.write_volatile((port::task_exit as *const ()).addr());
task.sp = sp.offset(-36).addr();
}
}
}
Cortex-M3/4
- 中断服务程序部分
#[exception]
unsafe fn SVCall() {
asm!(
"
ldr r3, =CURRENT_TASK_PTR
ldr r1, [r3]
ldr r0, [r1]
ldmia r0!, {{r4-r11}}
msr psp, r0
isb
mov r14, #0xfffffffd
bx r14
"
)
}
/// 如果由Systict异常触发,那么xPSR、pc、sp等自动保存在主栈中
/// 如果由任务触发,那么xPSR、pc、sp等自动保存在任务栈中
#[exception]
unsafe fn PendSV() {
/// 不要调用任何函数,否则会改变r14的值,导致无法回到任务栈中
asm!(
"
mrs r0, psp
isb
ldr r3, =CURRENT_TASK_PTR
ldr r2, [r3]
stmdb r0!, {{r4-r11}}
str r0, [r2]
stmdb sp!, {{r3, r14}}
cpsid i
cpsid f
bl switch_context
cpsie f
cpsie i
ldmia sp!, {{r3, r14}}
ldr r1, [r3]
ldr r0, [r1]
ldmia r0!, {{r4-r11}}
msr psp, r0
isb
//恢复msp
ldr r0, =0xE000ED08 // 向量表地址,将 0xE000ED08 加载到 R0
ldr r0, [r0] //将 0xE000ED08 中的值,也就是向量表的实际地址加载到 R0
ldr r0, [r0] //根据向量表实际存储地址,取出向量表中的第一项,向量表第一项存储主堆栈指针MSP的初始值
msr msp, r0 //将堆栈地址写入主堆栈指针
bx r14
"
);
}
/// 系统节拍器中断
#[exception]
unsafe fn SysTick() {
const TICKS: u32 = SYSTICK_CLOCK_HZ as u32 / TICK_CLOCK_HZ as u32;
interrupt::free(|_| {
let tick = core::ptr::read_volatile(&SYSTICKS);
core::ptr::write_volatile(&mut SYSTICKS, tick + TICKS as u64);
if scheduler::systick() {
cortex_m::peripheral::SCB::set_pendsv();
}
});
}
/// 软中断切换任务
#[export_name = "switch_context"]
unsafe extern "C" fn switch_context() {
scheduler::schedule();
}
/// 所有任务的退出函数,调用exit函数即可
pub(crate) unsafe extern "C" fn task_exit() {
scheduler::exit_current_task();
}
- 移植层实现部分
impl Portable for STM32F1Porting {
/// 完全内存屏障
/// 保证在屏障之前的任何存储操作先于屏障之后的代码执行。
fn barrier() {
cortex_m::asm::dsb();
}
fn free<F, R>(f: F) -> R
where
F: FnOnce(&CriticalSection) -> R,
{
unsafe { cortex_m::interrupt::free(|_| f(&CriticalSection::new())) }
}
/// 开全局中断
fn enable_interrupt() {
unsafe { cortex_m::interrupt::enable() }
}
/// 关全局中断
fn disable_interrupt() {
crate::arch::cortex_m::interrupt::disable()
}
/// 启动调度器
fn start_scheduler() -> ! {
//配置中断,这个函数就是定时中断和软中断使能
log::info!("Start scheduler");
//从任务栈恢复CPU状态,汇编实现
unsafe {
setup_intrrupt();
asm!(
"
mov r0, #0
msr control, r0 // sp=msp
cpsie i //使能全局中断
cpsie f //使能全局异常
dsb //数据同步,将流水线中的数据全部执行完毕
isb //指令同步,将流水线中的指令全部执行完毕
svc 0xff //调用SVCall异常服务,在SVCall里恢复第一个任务
nop
"
)
};
panic!("~!@#$%^&*()_")
}
/// 软中断
fn irq() {
cortex_m::peripheral::SCB::set_pendsv();
cortex_m::asm::dsb();
cortex_m::asm::isb();
}
fn disable_irq() {
cortex_m::peripheral::SCB::clear_pendsv();
}
/// 获取rtc tick
fn systick() -> u64 {
unsafe { core::ptr::read_volatile(&port::SYSTICKS) }
}
/// 硬件延时,单位us
fn delay_us(us: u64) {
let clock = (us * (CPU_CLOCK_HZ as u64)) / 1_000_000;
cortex_m::asm::delay(clock as u32);
}
/// 保存任务环境到任务栈
fn save_context(task: &mut Task) {
unsafe {
//任务栈指针移到栈顶,也就是数组的最后一个元素起始位置
let mut sp = task.stack.add(task.stack_size - 1);
// sp = (sp.addr() & !0x0007) as *mut usize;
sp = sp.offset(-1);
sp.write_volatile(0x01000000); /* xPSR */
sp = sp.offset(-1);
sp.write_volatile((task.entry as *const ()).addr()); /* PC */
sp = sp.offset(-1);
sp.write_volatile((port::task_exit as *const ()).addr()); /* LR */
sp = sp.offset(-5); /* R12, R3, R2 and R1. */
sp.write_volatile(task.args.addr()); /* R0 */
sp = sp.offset(-8); /* R11, R10, R9, R8, R7, R6, R5 and R4. */
task.sp = sp.addr();
}
}
}
参考实现
Xtask这份参考实现在RISC-V和ARM芯片上都可以跑通,如果您有一块GD32VF103或者Cortex-M3/4的开发板+调试器/仿真器,那么你就可以试着跑一下example目录中的示例了,你也可以通过调试器观察到多个任务在交替执行,且看上去是在同时运行的

几块跑通的单片机实物图
调试器输出
工程应用
Xpilot这个工程是为了验证Xtask在实际应用环境正确性,外部中断能不能与Xtask调度器融洽的工作以及调度器的工作效率(肉眼能观察的那种),实现了IMU数据的采样,同时通过USART总线(串口)发送到上位机上实时观察飞行器的飞行姿态和欧拉角工作曲线
Ext Link: https://github.com/gqf2008/xtask
评论区
写评论--
👇
overheat: 在运行main()之前是不是要用汇编配置不同的芯片? 是的,RUST嵌入式官方组已经帮我们实现好了常用指令集架构的运行时库(rt),移植的时候看下对应芯片的启动汇编,稍做修改应该就可以了
RUST嵌入式工程组
在运行main()之前是不是要用汇编配置不同的芯片?
先来一个赞👍,然后在看
多谢分享,抱拳