Linux 内核中首个 Rust 代码 CVE 漏洞
- 事件概述
- 里程碑事件:Linux 内核为其 Rust 代码部分分配了首个 CVE 编号(CVE-2025-68260)。
- 受影响组件:该漏洞出现在 Android Binder 的 Rust 重写版本驱动中。
- 漏洞性质:这是一个**竞争条件(Race Condition)**漏洞。
- 具体原因:涉及被标记为
unsafe(不安全)的 Rust 代码部分。具体来说,代码中的逻辑在处理链表指针时存在缺陷,可能导致内存损坏(Memory Corruption)。 - 影响:目前评估主要会导致系统崩溃(DoS,拒绝服务),虽然理论上涉及内存损坏,但尚未证实能导致远程代码执行(RCE)。
- 背景:相比于同期 C 语言代码中发现的数百个漏洞,这是 Rust 代码引入内核数年来发现的第一个正式 CVE。
- 技术细节
- 核心问题:漏洞出在侵入式双向链表(Intrusive Doubly-linked Lists)的实现上。这是内核开发中常见但很难在 Rust 中安全抽象的数据结构。
- 触发逻辑:
- 在
Node::release函数中,代码试图遍历一个列表。 - 同时,
NodeDeath::set_cleared函数试图将自己从该列表中移除。 - 由于锁(Locking)和
unsafe块中的假设不一致,导致了数据竞争。
- 在
- 关于 Unsafe:社区指出,虽然漏洞发生在 Rust 代码中,但它准确地发生在
unsafe块及其相关的抽象层中。这并没有打破 Rust 的安全承诺,反而验证了 Rust 的设计哲学——将内存安全问题限制在显式的unsafe块中,而不是像 C 语言那样散布在整个代码库里。 - 修复方式:修复实际上修改了“安全”代码部分(移除了
core::mem::take),因为之前的安全代码破坏了unsafe块所依赖的不变性(Invariant)。
- 社区观点与评论
- 并不意外:大多数开发者认为这是预料之中的。Rust 无法消除逻辑错误,尤其是在必须使用
unsafe与底层内核结构交互时。 - “Rust 失败了吗?”:社区普遍反驳了这种观点。
- 对比:有评论指出,“这是数年开发中的 1 个 CVE,而 C 代码同类问题不计其数”。
- 隔离性:漏洞被隔离在特定的 unsafe 模块中,使得审查和修复比 C 语言的全局指针问题更容易。
- 复杂性讨论:部分讨论集中在“在 Rust 中编写内核级链表确实很困难”,因为 Rust 的所有权模型与内核这种高度依赖共享可变状态的设计存在冲突,需要极高水平的
unsafe抽象能力。 - CVE 泛滥背景:也有人指出,Linux 内核团队(如 Greg KH)最近成为了 CNA(CVE 编号授权机构),开始给大量内核 Bug 分配 CVE,因此“首个 Rust CVE”更多是流程上的必然,而非 Rust 代码质量突然下降。
总结:
这是 Linux 内核 Rust 进程中的一个正常插曲。它证明了 Rust 不是“魔法”,无法自动修复人类在 unsafe 块中写下的错误逻辑,但也证明了 Rust 有效地缩小了内存安全问题的排查范围。这个 CVE 主要是一个健全性(Soundness)漏洞,源于对底层链表操作的封装不够完美。
文章《Rust GCC 后端:why and how》
作者:Guillaume Gomez
文章深入探讨了 Rust 的 GCC 后端(rustc_codegen_gcc)的设计初衷与实现原理。
- 背景:编译器的“前端”与“后端”
- 前端(Front-end):负责读取源码、解析语法(AST)、检查类型(HIR)、执行借用检查(MIR)等。这部分确保代码在逻辑和语义上是正确的。
- 后端(Back-end/Codegen):将前端生成的中间表示(AST/MIR)翻译成特定处理器的机器码。Rust 默认使用 LLVM 作为后端,但也支持 Cranelift 和 GCC。
- 为什么需要 GCC 后端?(The Why)
- 架构支持:GCC 诞生于 1987 年,比 LLVM(2003 年)久远得多。它支持许多 LLVM 不支持的老旧或特殊处理器架构(例如文章提到的 Dreamcast 游戏机)。
- 兼容性:为了让 Rust 运行在这些“只有 GCC 能驱动”的平台上,开发 GCC 后端是唯一的途径。
- 项目辨析:
gccrsvsrustc_codegen_gcc文章澄清了两个极易混淆的概念:
gccrs:这是用 C++ 为 GCC 编写的一个完整的 Rust 前端。它需要从头重新实现解析、类型检查、借用检查等所有功能。rustc_codegen_gcc(本文主角):它是官方rustc编译器的一个插件/后端。它直接复用官方成熟的前端(解析、借用检查等),只把生成二进制代码的环节交给了 GCC。
- 技术实现(The How)
- 核心库
libgccjit:虽然名字里有“JIT”,但它支持 AOT(提前编译)。它是 GCC 提供的一个 API,允许其他程序(如rustc)调用 GCC 的代码生成能力。 - 实现机制:
rustc提供了一个抽象接口rustc_codegen_ssa,定义了后端必须实现的 Trait(如CodegenBackend)。- 作者通过示例展示了如何实现
const_str:在 GCC 后端中通过缓存字符串、调用libgccjit的 API 创建字符串常量,并处理指针转换。
- 优化传递:后端不仅是简单的翻译,还会向 GCC 传递元数据。例如,Rust 知道引用(Reference)永远不为
NULL,后端会向 GCC 添加nonnull属性,从而让 GCC 在最终优化阶段减掉不必要的空指针检查,提高生成的代码性能。
- 总结
GCC 后端的主要价值在于极大地扩展了 Rust 的硬件版图,同时通过复用
rustc的前端,保证了与标准 Rust 行为的一致性,而不需要像gccrs那样辛苦地重新实现所有语言特性。
阅读:https://blog.guillaume-gomez.fr/articles/2025-12-15+Rust+GCC+backend%3A+Why+and+how
文章《献给 Rustdoc 团队的礼物》
这篇文章是知名 Rust 博主 Amos (fasterthanli.me) 发布的,详述了他为了解决 Rust 文档(docs.rs 和 rustdoc)中语法高亮功能匮乏的问题,而开发的一套名为 Arborium 的解决方案。
- 核心痛点
- 现状:目前的
docs.rs对非 Rust 语言(如 HTML、SQL、JavaScript 等)的代码块缺乏高质量的语法高亮。 - 困难:现有的高亮方案往往不够智能或难以扩展。虽然
tree-sitter是目前的业界金标准(由编辑器使用),但将其集成到文档生成中非常复杂,涉及编译多种语言的语法文件(Grammars)、处理 WASM 兼容性以及系统依赖等问题。
- 解决方案:Arborium Amos 开发了 Arborium 项目,这是一个旨在解决上述问题的“大礼包”。
- 功能:它打包并修复了 96 种编程语言的
tree-sitter语法解析器。 - 特点:
- 统一接口:提供简单的 API 将代码高亮为 HTML。
- 跨平台:支持编译为 WASM(可在浏览器运行)和本机代码。
- 开箱即用:内置了所有必要的查询文件(highlight queries)和依赖。
- 三种集成方案(“礼物的打开方式”) Amos 提出了三种将 Arborium 应用于 Rust 文档生态的方式:
-
方案一:前端注入(目前可用)
- 做法:用户在
Cargo.toml中配置,通过注入 JS 和 WASM 文件,在浏览器端动态渲染高亮。 - 优点:不需要修改
docs.rs基础设施,立即能用。 - 缺点:用户需下载较大的 WASM 文件,且存在潜在的供应链安全风险(如果脚本被篡改)。
- 做法:用户在
-
方案二:直接集成进
rustdoc(官方 PR)- 做法:Amos 提交了一个 PR,将 Arborium 直接编译进 Rust 官方文档工具
rustdoc中。 - 优点:生成静态 HTML,无客户端负担。
- 缺点:会导致
rustdoc二进制文件体积显著增加(因为包含了几十种语言的解析器)。
- 做法:Amos 提交了一个 PR,将 Arborium 直接编译进 Rust 官方文档工具
-
方案三:后端后处理(推荐方案)
- 做法:使用新工具
arborium-rustdoc,在docs.rs服务器构建文档后,对生成的 HTML 进行后处理(Post-processing)。 - 优点:速度快、安全(在服务器端运行)、不增加客户端体积、不影响
rustdoc及其编译速度。 - 结论:这是作者最推荐给 Rust 文档团队的方案。
- 做法:使用新工具
- 总结
Amos 通过极其繁重的工程化工作(解决 CI 构建、libc 依赖、WASM 兼容等),为 Rust 社区提供了一套现代化的、基于
tree-sitter的文档高亮基础设施。这使得未来的 Rust 文档可以像现代 IDE 一样,为内嵌的 SQL、HTML 或其他语言代码提供完美的语法着色。
阅读:https://fasterthanli.me/articles/my-gift-to-the-rust-docs-team
演讲:SQLx Talk @ Svix SF Rust Meetup
SQLx 作者在演讲中简要介绍了 SQLx 的历史,回顾了目前面临的挑战,并谈到了近期计划。
幻灯片、链接、注释和勘误表: https://github.com/launchbadge/sqlx/discussions/4124
观看:https://www.youtube.com/watch?v=ZC7UcfBp2UQ
iced_plot:GPU 加速的 iced 绘图库
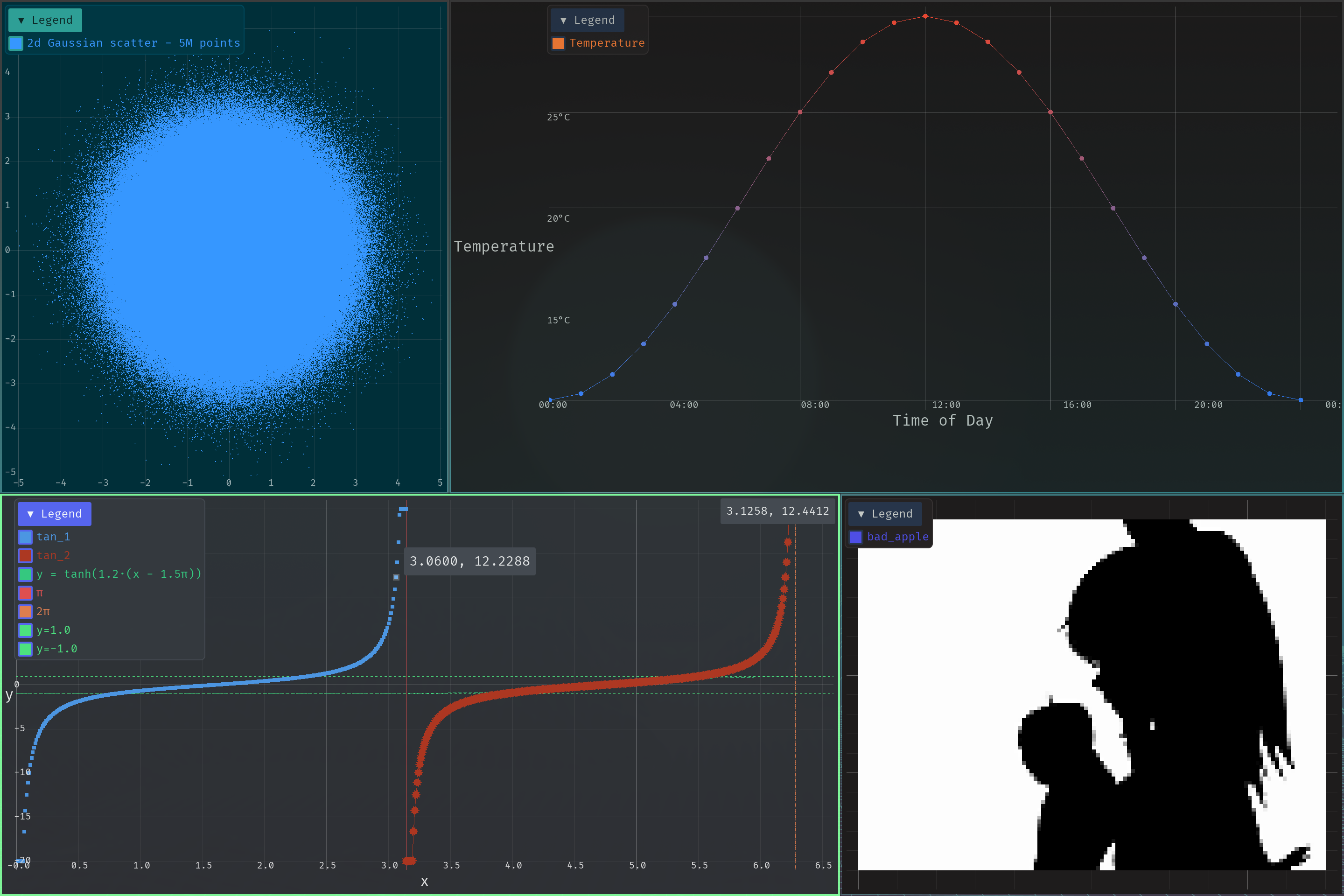
我非常喜欢 egui ,多年来一直用它来制作可视化工具。虽然它功能强大,但如果数据量很大, egui_plot 很快就会出现性能问题。这对于某些使用场景来说会非常令人沮丧。
为了尝试一些新东西,我决定为 iced 构建一个保留模式的交互式绘图组件。它拥有一个自定义的 WGPU 渲染管线,并且(与 egui_plot 等组件不同)所有数据都保留在顶点缓冲区中,除非数据发生变化。这使得它的速度非常快。使用 iced 非常愉快,而且熟悉 Elm 架构的过程也很有趣。
- 可处理大型数据集(高达数百万个数据点)
- 在帧之间保留 GPU 缓冲区,以实现快速重绘和拾取。
- 坐标轴/标签、图例、参考线、工具提示、十字线、坐标轴链接等。
仓库:https://github.com/donkeyteethUX/iced_plot
--
From 日报小组 苦瓜小仔
社区学习交流平台订阅:
评论区
写评论还没有评论